论文:关于乐观并发控制方案的观察研究
此论文题目为:observations on optimistic concurrency control schemes
摘要
OCC的一个假设前提是,事务过程中的读写冲突是非常少的。在事务提交之前,需要校验是否有冲突发生。冲突发生的解决方案主要是事务回滚。本论文主要介绍和比较了两种OCC方案,并且研究了一些实现上的细节,以及与两阶段锁协议的优缺点比较。
简介
先定义事务串行化的概念:be serializable or has the property of serial equivalece if there exists at least one serial shedule of execution leading to the same results for every transaction and to the same final state of the database. (注解:这一概念的定义与前面介绍OCC文章中对此的定义是非常相似的,可以直接参考)。
传统使用两阶段锁协议。论文On Optimistic Control Methods for Concurrency Control指出了这种方法存在的一些缺点。
OCC基本原则
OCC的设计是为了减少加锁负载,它的一个假设前提是:事务中的冲突是非常少见的。因而,它把冲突检测延迟到了事务提交的时间点。一旦发生冲突,该事务就撤消回滚。OCC把事务分成了三个阶段:read phase; validation phase; write phase。其中, read phase的结束对应了DBMS的EOT(end of transaction)。
Read phase
对于每一个事务,都对应一个事务缓存(transaction buffer),该缓存由DBMS来控制和维护。只读对象可能存在于该缓存中,也可能不存在; 如果一个对象不存在缓存中,就需要从system buffer或者磁盘上来读取该对象。然而,被修改的对象是肯定存在于事务缓存中的;一个事务中,对同一个对象的反复修改是在本地副本上进行的。
事务修改的粒度可以是页,也可以是记录。使用前者冲突会更大,一般使用后者。(备注:在该阶段,如果要直接对全局数据库对象进行修改,而又不想采取加锁策略,就需要使用时间戳方案,这是另一类的并发控制了)。
Validation phase
这个阶段检查是否与其他并行事务发生冲突。如果确定发生冲突,则该事务回滚; 否则的话, 该事务正常提交。
Write phase
只读事务不存在此阶段,只有写事务才有。在这个阶段,需要REDO日志来防止介质故障,可以在2PC协议的第一个阶段完成。
此阶段所述的“写”并不是指把数据刷到磁盘上,而是指数据的变更直接全局可见。
Validation of Serial Equialence
为了验证串行化准则,需要为事务赋于一个唯一的事务号Ti,赋值时间点可以在read phase的结束时,也可以延迟到验证成功之后。每次赋于事务号之后,TNC(事务号计数器)就自增1。If Ti finishes its read phase before Tj (i.e. Ti is validated before Tj), then Ti < Tj holds. ( 如果Ti在Tj之前结束了read phase,那么就说Ti < Tj是成立的)
为了能够串行化,事务Ti和Tj必须遵守下面的两个规则:
- 规则1:no read dependency 不存在读依赖
- 规则1.1: Ti不会读取被Tj修改的数据;
- 规则1.2:Tj不会读取被Ti修改的数据;
- 规则2:no overwriting 不存在覆盖写
- Ti不会去覆盖写已经被Tj写入的数据,反之亦然。
有两种基本方法来保证规则1和规则2:
- Ti和Tj之间没有时间重叠;
- Ti和Tj之间没有数据重叠(对象集没有重叠);
- 前两条可以分别适用于读集合和写集合,从而构造更多的协议。
这引出了如下的OCC可替代方案:
- no time overlap at all 时间上根本没有重叠。 事务Ti和Tj完全是顺序是执行的,直接保证了规则1和规则2。
- no time overlap of write pahse 写阶段没有时间重叠。
- Tj事务不会读取已经被Ti修改了的数据。 这保证了规则1.2;
- Ti完成了写阶段,之后Tj才开始了写阶段(没有时间重叠; Tj不能够影响Ti的读阶段)。这保证了规则1.1和1.2。
- no object set overlap of write sets 写集合不存在对象重叠
- Tj事务不会读取已经被Ti修改了的数据。 这保证了规则1.2;
- Ti事务不会读取已经被Tj修改了的数据。(Ti读阶段和Tj写阶段不存在时间重叠;Tj不能够影响Ti读阶段)这保证了规则1.1;
- Ti和Tj的写集合是分离的(没有数据重叠从而允许写阶段的并发执行)。这保证了规则2。
- no object set overlap of read sets and write sets
- 完全无依赖允许并发执行,从而保证了规则1 和规则2。
论文On Optimistic Control Methods for Concurrency Control对前三种可选方法同样进行了别样论述。方法1是显而易见的。 方法2提供了OCC的最基本方法,下面的两种不同方法正是基于方法2进行论述的。
Backward Oriented OCC
BOCC在事务Tj的validation阶段检查它的读数据RS(Tj)是否与任何一个事务Ti的写数据WS(Ti)有交集,而Ti与Tj是并发执行的、并且早于Tj结束了读阶段。
假定Tj开始的时候,Tstart为给其他事务赋值的最大号;当Tj进入validation阶段时,此时的最大事务号为Tfinish。那么下边的伪代码将说明事务Tj的验证过程,并决定事务Tj的命运。
valid = true;
for Ti = T<sub>start+1</sub> TO T<sub>finish</sub>
{
if RS(Tj)与WS(Ti)的交集不为空,then
valid = false;
}
if valid then commit
Else abort
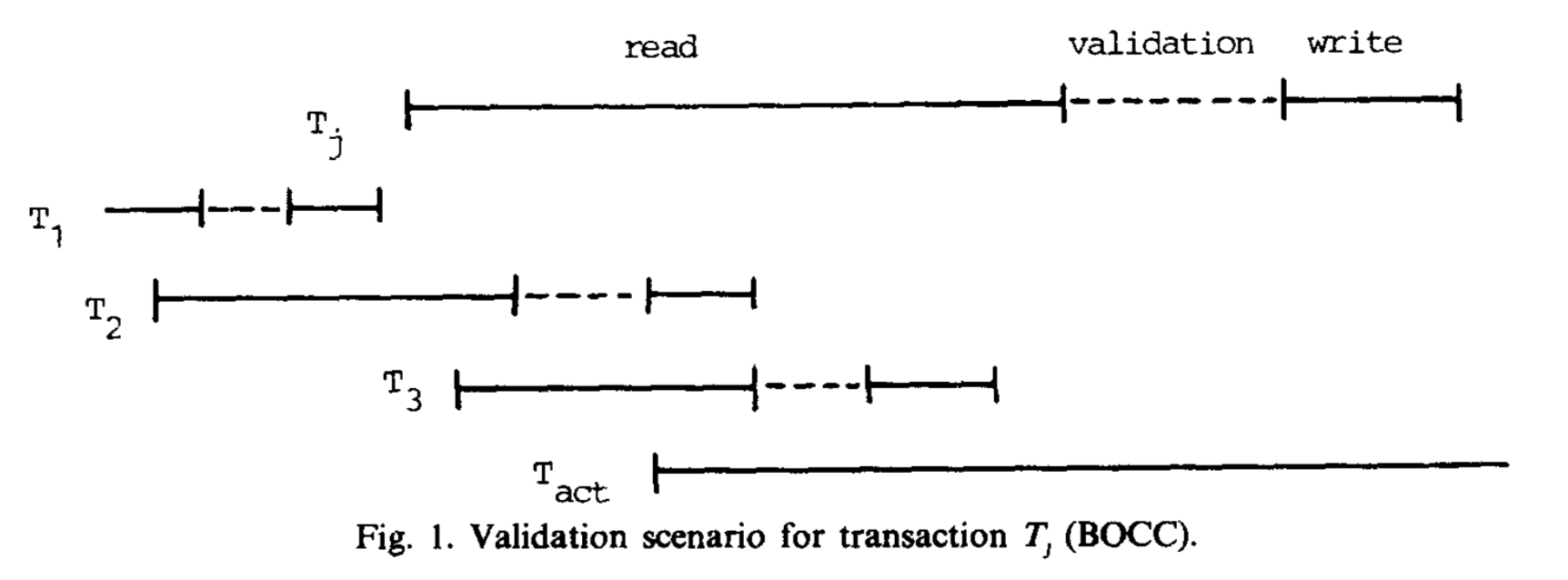
在上面的图中,需要检验事务Tj的读数据与事务T2+T3的写数据。因为这两个事务已经提交了,如果数据存在交集的话,唯一的解决冲突的方案就是回滚事务Tj。
这个过程允许在一个时刻仅有一个validting and committing的事务。 如果其他事务想要提交的话,就必须等待直到进入这个临界区后执行;在临界区中,就可以处理这个事务与其他事务的读阶段了。很明显,如果没有这个临界区的话,事务的validation就可能会进入到一个无限重复需要检验的过程中。
需要注意的是,不再需要关注已提交事务的读集合,但是重叠事务的所有写集合是需要保留的,直到它们的最后一个并发事务结束了。显然,对于一个有大量写的长事务而言,这个要求是相当不易满足的。
Forward Oriented OCC
FOCC在事务Tj的validation阶段检验它的写集合WS(Tj)是否与所有事务Ti的任一读集合RS(Ti)有交集,事务Ti此时还尚未完成它们的读阶段。这种策略保证读集合总是干净的。如果写集合与所有其他活跃事务的读集合无冲突,写集合才能够propagated。
检验过程的伪代码如下:
valid = true
for Ti = Tact1 TO Tactn DO
if WS(Tj) 与RS(Ti)的交集不为空, THEN
valid = false
IF valid then commit
ELSE resolve confiict
FOCC将并发控制的担子放在子写事务上。它要求只有快要结束的写事务需要进行测试是否满足串行化验证。所以,读事务一旦到了EOT(end of transaction),将自动提交。
解决冲突的策略主要有:
defer due to conflicting readers
如果冲突事务的集合中都是读事务,那么可以延后事务Tj。当所有的读事务都结束的时候,冲突就结束了,retry事务Tj的validation。这种策略明显是一种乐观的方法,如果新的读事务还与Tj冲突、源源不断到来的时候,事务Tj就有可能无限期地被延迟下去。
defer due to conflicting wirter
如果冲突事务的集合中有部分是写事务的话,延后策略可能提供了一种无伤害的冲突解决方案;其前提是,冲突写事务的定集合与事务Tj的写集合是分离的、没有交集的。那么,在冲突事务提交 之后,延迟的事务Tj再重做。这种策略同样也体现的是一种乐观的思想。
kill and commit
因为所有的冲突事务并未提交,所以可以选择一个事务将其结束移除。假设Tj是一个长写事务,而另一个冲突事务刚刚开始执行,这种情况下就可以选择这种方案。
abort
直接将事务Tj回滚掉。
在具体的系统实现方案中,可以采取上面的几种策略组合。
FOCC的关键点是,无论何时一个写事务提交,都需要与不断变化的读集合进行check。可靠的做法是,在一个临界区内对所有的活跃事务列表进行,然而这对性能是很大的伤害。
比较BOCC与FOCC可以观察如下:
- 写集合通常是读集合的一个小的子集。如果不是的话,新插入的数据片断会导致记录级别的冲突;
- BOCC必须将自己的读集合(潜在性的量大)与旧的写集合(潜在性的数目多)进行比较。二者都会随着事务检验的持续而增长;
- FOCC不检验读集合。它将自己的写集合与其他事务的写集合(读集合的一小部分)进行check。
- FOCC策略中的validation更困难,因为在读阶段中允许并发行为其代价更大,检测的是一个不断变化 的集合。与BOCC相比,check频率会少一些。
实现上的考虑
实现的层次主要有两个:数据模型的高层次对象,像记录; 存储结构层次的对象,像页面。
记录层次的CC要求被修改的记录一直保持到写阶段执行完成。这样的话,就需要管理事务修改的对象,并且这些对象要具有NOSTEAL属性;也就是说,对应的页也要保持在系统缓存中,直接执行了写阶段。假设不这样做的话,在这个事务的生命周期过程中,一旦这个页被淘汰出去,临界区再次需要的进修就需要从磁盘中再次读取。FORCE策略也是应该避免的(在EOT时把所有修改过的页写入到磁盘上),这是因为所有页应该是在写阶段中必要的时候才写下去的。所以,COMMIT处理上,看起来是要采用NOSTEAL/NOFORCE的策略。
页面层次的CC在读阶段就把所有修改准备好了,所以可以获得更短时的写阶段。使用NOSTEAL/NOFORCE策略的话,写阶段只需要实现将修改的页面在系统缓存中全局可见即可。即使使用了STEAL/FORCE策略,可以加上一些ATOMIC方案(例TOSP)来获得易接收的COMMIT处理时间。这种机制意味着:
- 在读阶段会暂时性地把事务缓存中的修改页面写入到磁盘上;
- 为了避免页表块的同步IO,需要对已经修改的、页表的项添加一些日志技术;
- 在validation成功后的写阶段中,需要自动将页面集合propagate出去。
无论是哪种情况,COMMIT processing的性能问题必须是实现上要考虑的一个关注点。
为了加速validation过程,需要为主存中的数据结构体进行详细地设计。首先是事务中的RS和WS,这两个结构体要支持必要的merge操作和比较操作。要想高效地比较,可以考虑采用bit list。再考虑到它们的大小,可以考虑采用压缩、encoding/decoding。实现上要对这些做一些权衡。
BOCC方案必须保留与运行中事务在一段时间上重叠的、所有已提交事务的WS信息。要维护这样一个全局的WS链表或者表是很困难的,因为涉及到GC(垃圾回收)。因此,可以参考一下论文中给出的一个图3方法。
FOCC策略的实现问题要少一些,保留所有活跃事务的RS和WS就已足够了。当允许读阶段的操作并行的话,check就会变得复杂了,因为此时RS是动态变化的;可以采取这样的一种方案,再加上额外的链接来搜集新来的并发读。然后在临界区的第二个阶段中check这个额外的链表。
OCC方案的一些特性
事务回滚的简单性
使用带了事务缓存的CC方案更容易实现事务的回滚,回滚的原因可能是用户错误、数据错误、检验失败、timeout等。
事务回滚的比率高
加锁方案中冲突的解决方案是锁等待,或者死锁检测和死锁解决。而OCC方案中冲突解决则是很高效的回滚。
一般认为,锁等待是可以减少事务冲突的风险。所以,与加锁方案相比,OCC的事务回滚占比要更高。有论文显示,加锁方案的回滚比率为10%,OCC方案的回滚比率为36%。
fair scheduling
失败事务再次执行时,还有可能再失败。要获得fair scheduling需要采取一些适当的冲突解决策略。BOCC的策略就是简单的回滚。
FOCC的策略则要更有弹性。kill策略在validation没有失败的情况下,可以达到较高的吞吐量。要对失败回滚多次的事务特别关注,对于采取的简单kill策略可以做一些相应的调整。
need of serialization
失败的事务在最坏的情况下,需要重新执行,也可能是一而再、再而三地失败、重执行。To limit the thrashing situations and to solve the livelock prevented by using hierarchical locks, e.g. at the problem, these critical transactions must be enabled relation or segment level. On the other hand, the to commit with a few restarts in the worst case. 也可以采取一些加锁协议来实现strict serialization。另外,也可以使用一些负载平衡算法。
storage overhead
存储上的overhead主要考虑虚拟内存中的tokens/records/pages。
control of phantom problems
OCC无法提供full consistency。
如果不采取特殊的保持措施,幻影问题是无法阻止的。幻影问题的原因有:1) 对象不存在; 2) 并发创建了与之有语义关系的新对象。例如,在读操作中某些记录丢失了,之后又被其他事务插入了新记录,最后原生事务又重新读取了该记录。这种问题可以采取一些措施来做相应的消减。
在加锁方案中,可以采取层级加锁来阻止该问题的发生,像如关系层(relation level)、段层次(segment level)。换句话说,锁的粒度应该尽可能地小。可以引入记录(entry)层次的锁来阻止丢失记录的问题。这可能包括了:
- 对索引结构中的键范围进行加锁;
- 对链表结构中的前驱和后继进行加锁;
- 对文件中的EOF进行加锁;
- 对TID进行加锁,等等
如果没有特殊的访问路径来决定不存在记录的位置,那么层级加锁方案可以帮助阻止幻影问题的出现。例如,对于表扫描来讲,可以对整个表加锁。可以将这些技巧引入到OCC方案中。
在记录/页面层级作如此的加强看起来也不能够提供解决幻影问题的能用方案。假设一个表扫描保留了所有访问的页的token;当底层段允许动态增加时,就可能会有问题了。所以,需要对OCC方案进行一个扩展了;例如,可以模拟层级锁一样,对于token也进行层级处理。然而这个方法是有争论的,它违背了乐观的宗旨,因为它有可能会引起更大粒度的冲突。
time-consuming FORCE schemes
如果事务修改了的对象在EOT时候强制要物化到磁盘的数据库上(以防止由于系统crash而导致的partial redo),那么:1) 记录级CC,以同步方式执行会引起潜在的长延时; 2) 页级CC,与ATOMIC结合使用弹性会更好。
deferred checking of consistency constraints
deferred modification of access path data
complexity of query processing
use of record-level CC
drawbacks of page-level CC
与加锁方法的比较
加锁方案保证任一时刻点数据库的镜像是一致的。正因为如此,该方案可能牺牲了潜在的并行度。然而,这些方案可以提供了这样的能力:你可以选择合适的控制层次来减少竞争想关的问题。
为了增强并发, OCC允许事务执行过程中产生私有的数据副本。OCC核心问题在于commit处理时对这些副本进行merge,从而需要获得一个事务一致性的数据库镜像。正如前面所讨论,当这些副本不匹配的时候,产生了一系列的问题和困难。从数据库使用来看,OCC更应该使用page level。然而,加锁的方法并没有此类的限制,它还可以选择使用记录、甚至是字段的级别。
此外,为了减少commit处理或者减少主存使用,需要引入特别的假定(NOSTEAL/NOFORCE)。加锁方案同样没有这些要求和假定。
对于一些关注并发控制的设计决定,需要考虑下面的这些属性和要求:
- 热点数据需要串行化可控;
- 如果等待和死锁并很少见,加锁与OCC同样的好;
- 每一个系统需要一些控制层次从而提供高效地读写操作;
- 在处理记录“不存在”的问题上,加锁方法看起来更好些;