PostgreSQL之元组结构
在页结构讲完之后,理所当然需要说明的就是元组的结构。主要以堆元组的结构为主,索引元组的结构也并无差异,区别主要在于元组头的信息结构,列结构则大同小异。上图一目了然,如下:
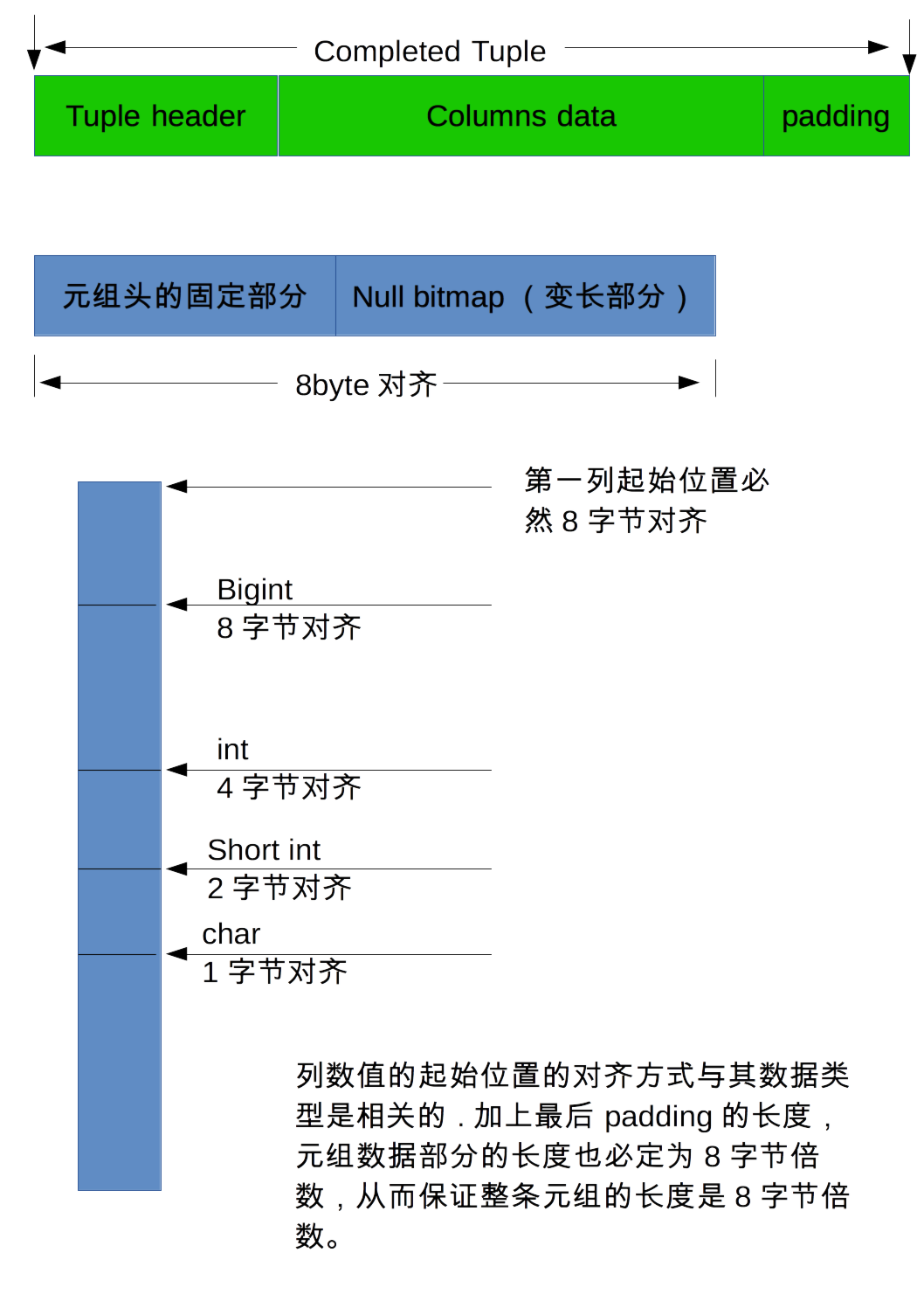
一个完整的元组主要由两大部分构成,元组头和列数据;其中,元组头部分是保证8字节对齐的,列数据部分也会填充相应的padding数据来保证这一点,所以整个完整的元组也是8字节对齐的。其实,在说到列数据的部分,是必定绕不开数据类型以及其元信息的(包括类型OID、对齐字节数目、字符串类型,等等);这一部分的信息也会在其中进行必要的说明。
备注:从代码实现来看,形成元组的函数heap_form_tuple()中,对于元组的整个大小和内存的分配并没有进行8字节的对齐;只是对于元组头的大小,显式地进行了8字节对齐操作。这样来看,元组的大小并不是8字节对齐的。但是,把元组向页内进行插入的时候,页内是为元组预分配了“元组长度的8字节对齐大小”的空间;并且一个新页的大小总是清0的,所以也就相当于是为整个元组8字节对齐了。两种理解都是可以接收的。
元组头
如上图所示,元组头部分也应该分为两个部分, 前一部分是固定长度部分,后一部分是变长部分;二者总长度还需要是8字节的倍数。所谓固定与变长,也其实是相对是否可以直接使用结构体这种方式决定来说的。
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union
{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a
* speculative insertion token) */
/* Fields below here must match MinimalTupleData! */
uint16 t_infomask2; /* number of attributes + various flags */
uint16 t_infomask; /* various flag bits, see below */
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
在如上所表述的元组头结构体中,t_hoff在内之前的所有结构属于固定部分; t_bits开始则属于变长的部分。
变长部分的长度由表定义中列的数目来决定,它记录了各个列对应值是否为null的关键信息; 当然,如果所有列都不存在null值的话,这一变长部分是不存在的,这一关键的信息会直接记录在固定部分的t_infomask中(不存在HEAP_HASNULL标识)。 如果有一个列的数值是null的话,标识HEAP_HASNULL就会存在, 那么这个变长部分就要存在,并且需要存储所有列的对应值是否为null,一个bit一个列,直接相当于是一个bitmap。其实这一部分还会存储一个系统字段, 就是OID列; 如果表定义中指定了其元组是需要OID系统列的话,最后的4个字节会用来存储该元组的一个OID数值。
t_hoff记录了整个元组头的字节数,包括了null bitmap和padding部分;当然也包括了系统列OID所占的空间。
t_infomask是一个比较重要的成员,它存储了相当重要的一些标识;这些标识主要包括两类标识:列数据存储方面的; 元组事务信息方面的。
- 列数据属性方面的主要有4个: 是否有空值,与null直接相关; 是否有变长列,直接与数据类型相关(定长数据类型和变长数据类型); 是否有外线存储(外线存储的部分再讲);该元组是否有自己的OID系统列的数值。
- 元组事务信息方面的,主要也是有6个:插入事务xid是否已提交; 插入事务xid是否无效; 删除事务xid是否已提交; 删除事务xid是否无效;该元组是否locked;该元组是否为一个更新后的元组。
t_infomask2这一部分主要存储了两部分信息:一部分是该元组中的实际列的数目; 另一部分是重要的标识信息。第一部分占用了11个bit,也就是说最大可存储2047,实际上支持的列的最大列数目为1600。另一部分是两个重要的标识,与HOT技术相关。当发生hot update的时候,旧元组会被打上HEAP_HOT_UPDATED的标识,而新元组则会被打上HEAP_ONLY_TUPLE的标识,以标明二者是HOT关联起来的两个版本的元组。
t_ctid这个部分则直接与元组的更新链是相关的。旧版本元组里这个字段存储了新元组的位置,它相当于一个指针的作用;当这个字段的实际数值与元组自身的位置是相等的时候,表明了它是更新链上的最后一个元组,表明了更新链的终结。需要注意的是,正常的普通更新链是可以跨越页的,而HOT是不跨越页、不同版本的元组是位于相同的页的。也正是这一点,导致了redirected item的存在。
结构体的第一个成员是一个联合体,最常见的是HeapTupleFields这部分的信息。它主要包括了三个成员信息:xmin, 插入事务的xid; xmax, 删除事务的xid; cid, 执行命令id。前两者要好理解一些,对于cid是与执行单条sql语句中、执行过程中不同的command相关的,每当执行一次command id ++时,就会有一个进入一个新的command中。
数据类型
PostgreSQL提供给用户层的数据类型是比较丰富的。此处主要是指内部的与存储相关的数据类型;一个数据类型主要涉及的属性包括了:类型名称;类型长度;是否为值传递;对齐字节。当然还有其他的属性,可以通过\d pg_type命令来查看的,这里主要关心我们所关注的、与元组存储相关的几个属性。
常见的数据类型有布尔类型、字节类型、字符类型、名字、整数类型、字符串类型、OID类型等;这在typname一列可以看到。
typlen表示了数据类型的长度信息。列为正值,表示实际数据类型的长度; 列为负数则表示变长类型,可选值有-1和-2.
- 布尔类型和字符类型,它的每一个数值占用1个字节。
- int2这类short int类的整数,它的每一个数值占用着2个字节。
- int4类的整数,它的每一人数值占用着4个字节。
- xid, 事务标识类型;
- tid, 元组标识ID,用于标识一个表内的元组位置。
- bigint/int8这种大整数则占用着8字节大小。
- name类型用来记录对象的名称,使用的是固定的64字节(当然末尾0字符)。
- -1表示的是变长数据,主要包括了其他定长数据类型和字符串数据类型、超长数据类型。
- -2表示的是C字符串类型,尾0结束的字符串。
typbyval是布尔属性,用于表示这些数据类型进行赋值操作、比较操作的时候,是否可以直接用整数类型的= == != >= <= > <这些操作符;这些类型基本都是整数数据,1/2/4/8这四种字节的整数。对于其他的非值传递数据类型,则必须有相应的比较函数和赋值函数。
tpyalign表示数据类型的字节对齐方式。c表示单字节对齐方式;s表示双字节对齐;i表示四字节对齐;d表示8字节对齐。所有的数据类型的对齐方式就这么四种。
下面截取了常见的一些数据类型以及它的主要属性。
zhangchaowei=# select typname, typlen, typbyval, typalign from pg_type order by oid;
typname | typlen | typbyval | typalign
---------------------------------------+--------+----------+----------
bool | 1 | t | c
bytea | -1 | f | i
char | 1 | t | c
name | 64 | f | c
int8 | 8 | t | d
int2 | 2 | t | s
int4 | 4 | t | i
text | -1 | f | i
oid | 4 | t | i
tid | 6 | f | s
xid | 4 | t | i
cid | 4 | t | i
在代码实现中,所有的数据类型使用了一种抽象的统一表示方法,即Datum,它的长度为CPU字长。在64位的机器下,它的长度为8字节,所有比8字节小的数值都会直接存储在这8个字节之内。除此之外,其他的超长数值以及变长数值都是使用Datum存储了一个指针类型,真正的数据存储在另外一个heap内存上。
那么这种变长的数据类型在磁盘上应该怎么存储呢?简单来讲,主要有两种存储格式,
- 1字节头,后面是数据部分
- 4字节头,后面是数据部分
无论是哪种数据存储格式,头部含有较为重要的信息,包括需要区别字节头长度、是否经过了LZ压缩等信息。
列数据部分
上面说明了数据类型的基本重要知识。各个列的排列将会遵守对应的数据类型的要求,包括对齐方式,然后依序放置数据即可。在对元组访问的时候,为了加速元组的访问,使用了一个cached offset的信息,它表示了对应列在元组中的偏移位置是不会随着数据的变化而变化的。也正是因为这一点,这个cached offset也仅对表定义中、前面连续的、定长的列是有效的;一旦出现一个变长的数据列,必然会影响后续列访问的偏移位置,后面列的访问强依赖于前面变长数据的实际长度;当然,还有一个特性是会影响cached offset的,那就是null,如果列属性中出现了可为null的约束,那么null bitmap也是会影响到cache offset的;仅有非null的约束、在所有元组上共有的特征,这才能够利用上cached offset加速特性。这一优化给我们的提示是: 定长的数据类型放在表定义的前面,变长的数据类型放在表定义的后面,对于快速地访问元组属性列是有性能优势的。当然,所有列的访问除外。
对于这部分的信息,可以主要参考heap_form_tuple() + heap_deform_tuple()这两个函数。
彩蛋
cached offset在pg_attribute系统表中,其数值就是个摆设,默认为-1。当访问第一个元组的时候,才会根据实际的情况来进行更新填充每个字段的偏移量,一直碰到第一个null值,或者变长的数值,那么后面的列就不能再使用到cached offset了。那么,对于这种做法,能不能换另一个做法呢? 例如,直接在pg_attribute中记录每个字段在元组中应该的偏移量。想想也是可行的,只是如果第一个列是变长的列,那么这种种情况就会退化到pg当前的作法了。在其他情况下,只要表的前面列是定长数据类型,那么先不用管它有没有null值,可以先“乐观”地计算出每个列在不是null值的情况下的偏移量了。按这个想法来看,pg当前的作法就是一种比较”悲观”地做法了。这两种做法在效率上,按照原理来讲,没有太实质地变化,二者的效率是相差无几的。