PostgreSQL之MVCC
对PostgreSQL也学习了一段时间了,感觉到更多是要对已学习的知识进行总结和结构化,所以会慢慢地写一些关于数据库方法的文章。
背景
并发控制,本质上是读写并发的问题。在这之前,锁应该是最简单的实现并发控制的手段;可以通过共享锁和排他锁来控制对同一个对象的读写访问,它的特点是:读读共享,读写阻塞,写写阻塞。使用锁的一个最大问题是,写阻塞了读,读也会阻塞写;而这个场景在数据库中很常见的。
MVCC全称是Multiversion Concurrency Control(多版本并发控制)的缩写,从字面意义来看,就是为了解决并发控制的问题。 MVCC主要解决的就是上面所述的写阻塞读、读阻塞写的问题。使用MVCC之后,写不再阻塞读、读不再阻塞写。多版本概念是针对更新对象来讲的,在数据库中,最直接的更新对象就是元组(tuple),其实现也就是在元组上增加了相应的多版本信息;当读操作时,可以读取到对应版本的元组;当写操作时,不是对现有元组进行直接更新,而是使用一个拷贝进行。正是这样,实现了对同一个元组对象的多版本管理,从而实现了“写不阻塞读、读不阻塞写”,提高了并发。
实现
在不同的数据库里,其存储形式是不一样的,实现方式也不同。在PostgreSQL里,新老版本数据是混在一起的,Oracle和Innodb里是分开存储的,像Oracle有回滚段(UNDO段)。oracle的实现细节需要再了解,这里主要是说PostgreSQL的实现。
与MVCC紧密相关的一个概念是时间(点),这可以由真正的时间值来实现,也可以用一个递增有序的逻辑数值来表示。PostgreSQL中采用了后者,并同时来标识一个事务,即XID。当一个事务开始的时候,Postgres会增加XID值并赋给当前的事务,Postgres也会对系统里的每一个元组附上事务信息,这可以用来判断该行在其他事务中是否可见。
那么,XID在PostgreSQL中是怎么与MVCC挂起钩来着呢?这就要看最主要的insert/update/delete三个操作了; 其中,PostgreSQL对update的实现基本等同于delete+insert的。所以,等同地可以只看一下insert/delete是怎么使用XID的。主要的数据结构涉及两下,如下所详述。
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union
{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
当插入一个元组的时候,Postgres存储XID值并叫它 XMIN;这是一个隐藏字段,就专门地存储与insert相关的事务数值,参照上面结构体中的t_xmin成员。对当前事务来说,每一个XMIN值比当前事务的XID要小、并且该事务是已提交的元组,对于当前事务都是可见的。举个很简单的例子:你可以开启一个事务,假如以begin开始,然后插入几行数据,在Commit之前,这些数据对其他事务来说都是不可见的,直到你做了Commit。一旦我们做了Commit操作(XID会增长),对其他事务来说已经满足XMIN<XID,所以其他事务就能看到在该事务提交后的东西。获得当前事务的XID值比较简单:SELECT txid_current();
对于DELETE和UPDATE来说,MVCC的机制也是类似的,略有不同的是Postgres在执行DELETE和UPDATE操作时对每一个元组还存储了XMAX这一隐藏列。也是通过这个字段来决定当前的删除或者更新对其他事务来说是否可见。
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a
* speculative insertion token) */
/* Fields below here must match MinimalTupleData! */
uint16 t_infomask2; /* number of attributes + various flags */
uint16 t_infomask; /* various flag bits, see below */
------------- 只需要关注以上的结构成员即可 -------------------------
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
对于update操作,各个版本的元组是怎么样的联系起来的呢? 这是由上面结构中的t_ctid这个存储字段进行链接起来的,它就相当于链表中的指针作用一样。它的指向是从更旧版本的元组指向更新版本的元组;当这个值正好指向是自身的位置时,那么就表明已经遍历到了链的最后一个元组上了。
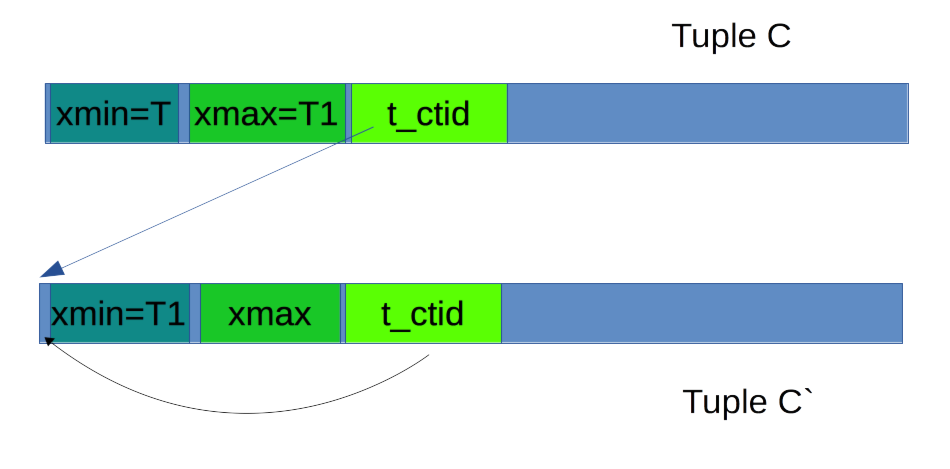
图中元组C是由事务T插入的,并且该事务已经提交;当事务T1对该元组进行更新时,生成一个新的元组C‘。那么事务T1就会将自己的事务标识打在元组C的xmax,同时在元组C’的xmin中打上自己的事务标识。这两个元组将会由字段t_tid关联起来,元组C里存储了新元组C’的位置,而C‘中存储的位置恰好指向自己的位置,来表明链表的终结。
还有一个需要关注的字段是t_infomask,它是一个辅助的信息,与上面XMIN+XMAX两个信息配合进行对照使用的,主要是目的是为了减少对CLOG文件的读取和访问,减少IO次数。这个字段的主要可用值如下:
/*
* information stored in t_infomask:
*/
#define HEAP_HASNULL 0x0001 /* has null attribute(s) */
#define HEAP_HASVARWIDTH 0x0002 /* has variable-width attribute(s) */
#define HEAP_HASEXTERNAL 0x0004 /* has external stored attribute(s) */
#define HEAP_HASOID 0x0008 /* has an object-id field */
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */
#define HEAP_COMBOCID 0x0020 /* t_cid is a combo cid */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */
/* xmax is a shared locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \
HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */
#define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */
#define HEAP_UPDATED 0x2000 /* this is UPDATEd version of row */
#define HEAP_MOVED_OFF 0x4000 /* moved to another place by pre-9.0
* VACUUM FULL; kept for binary
* upgrade support */
#define HEAP_MOVED_IN 0x8000 /* moved from another place by pre-9.0
* VACUUM FULL; kept for binary
* upgrade support */
#define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN)
#define HEAP_XACT_MASK 0xFFF0 /* visibility-related bits */
HEAP_XACT_MASK这个表示了在t_infomask中有多少bit是用于事务信息的,有多少bit是用于其他存储属性的。可以看出,低四位是用于存储属性的,其他的12位是用于事务信息的。其中,最主要的几个位信息为:
- HEAP_XMIN_COMMITTED, 表示insert事务已经提交
- HEAP_XMIN_INVALID, 表示insert事务已经回滚或者是无效的
- HEAP_XMAX_COMMITTED, 表示delete事务已经提交
- HEAP_XMAX_INVALID,表示delete事务已经回滚或者是无效的
- HEAP_UPDATED,表示该元组是update的新版本
- HEAP_XMIN_FROZEN, 表示这个元组已经被打上了frozen标识
从上面的这些信息里,也大体可以了解到在每条元组的事务信息区域时,同时存储了插入和删除事务的一些信息,并且对于事务的committed/rollback的状态有一些可用标识。
实例
先创建一个测试表:
CREATE TABLE test
(
id INTEGER,
value TEXT
);
开启一个事务,查询当前事务ID(值为3277),并插入一条数据,xmin为3277,与当前事务ID相等。符合上文所述——插入tuple时记录xmin,记录未被删除时xmax为0
postgres=> BEGIN;
BEGIN
postgres=> SELECT TXID_CURRENT();
txid_current
--------------
3277
(1 row)
postgres=> INSERT INTO test VALUES(1, 'a');
INSERT 0 1
postgres=> SELECT *, xmin, xmax, cmin, cmax FROM test;
id | value | xmin | xmax | cmin | cmax
----+-------+------+------+------+------
1 | a | 3277 | 0 | 0 | 0
(1 row)
继续通过一条语句插入2条记录,xmin仍然为当前事务ID,即3277,xmax仍然为0,同时cmin和cmax为1,符合上文所述cmin/cmax在事务内随着所执行的语句递增。虽然此步骤插入了两条数据,但因为是在同一条语句中插入,故其cmin/cmax都为1,在上一条语句的基础上加一。
INSERT INTO test VALUES(2, 'b'), (3, 'c');
INSERT 0 2
postgres=> SELECT *, xmin, xmax, cmin, cmax FROM test;
id | value | xmin | xmax | cmin | cmax
----+-------+------+------+------+------
1 | a | 3277 | 0 | 0 | 0
2 | b | 3277 | 0 | 1 | 1
3 | c | 3277 | 0 | 1 | 1
(3 rows)
将id为1的记录的value字段更新为’d’,其xmin和xmax均未变,而cmin和cmax变为2,在上一条语句的基础之上增加一。此时提交事务。
UPDATE test SET value = 'd' WHERE id = 1;
UPDATE 1
postgres=> SELECT *, xmin, xmax, cmin, cmax FROM test;
id | value | xmin | xmax | cmin | cmax
----+-------+------+------+------+------
2 | b | 3277 | 0 | 1 | 1
3 | c | 3277 | 0 | 1 | 1
1 | d | 3277 | 0 | 2 | 2
(3 rows)
postgres=> COMMIT;
COMMIT
开启一个新事务,通过2条语句分别插入2条id为4和5的tuple。
BEGIN;
BEGIN
postgres=> INSERT INTO test VALUES (4, 'x');
INSERT 0 1
postgres=> INSERT INTO test VALUES (5, 'y');
INSERT 0 1
postgres=> SELECT *, xmin, xmax, cmin, cmax FROM test;
id | value | xmin | xmax | cmin | cmax
----+-------+------+------+------+------
2 | b | 3277 | 0 | 1 | 1
3 | c | 3277 | 0 | 1 | 1
1 | d | 3277 | 0 | 2 | 2
4 | x | 3278 | 0 | 0 | 0
5 | y | 3278 | 0 | 1 | 1
(5 rows)
此时,将id为2的tuple的value更新为’e’,其对应的cmin/cmax被设置为2,且其xmin被设置为当前事务ID,即3278
UPDATE test SET value = 'e' WHERE id = 2;
UPDATE 1
postgres=> SELECT *, xmin, xmax, cmin, cmax FROM test;
id | value | xmin | xmax | cmin | cmax
----+-------+------+------+------+------
3 | c | 3277 | 0 | 1 | 1
1 | d | 3277 | 0 | 2 | 2
4 | x | 3278 | 0 | 0 | 0
5 | y | 3278 | 0 | 1 | 1
2 | e | 3278 | 0 | 2 | 2
在另外一个窗口中开启一个事务,可以发现id为2的tuple,xin仍然为3277,但其xmax被设置为3278,而cmin和cmax均为2。符合上文所述——若tuple被删除,则xmax被设置为删除tuple的事务的ID。
BEGIN;
BEGIN
postgres=> SELECT *, xmin, xmax, cmin, cmax FROM test;
id | value | xmin | xmax | cmin | cmax
----+-------+------+------+------+------
2 | b | 3277 | 3278 | 2 | 2
3 | c | 3277 | 0 | 1 | 1
1 | d | 3277 | 0 | 2 | 2
(3 rows)
提交旧窗口中的事务后,新旧窗口中看到数据完全一致——id为2的tuple排在了最后,xmin变为3278,xmax为0,cmin/cmax为2。前文定义中,xmin是tuple创建时的事务ID,并没有提及更新的事务ID,但因为PostgreSQL的更新操作并非真正更新数据,而是将旧数据标记为删除,并插入新数据,所以“更新的事务ID”也就是“创建记录的事务ID”。
SELECT *, xmin, xmax, cmin, cmax FROM test;
id | value | xmin | xmax | cmin | cmax
----+-------+------+------+------+------
3 | c | 3277 | 0 | 1 | 1
1 | d | 3277 | 0 | 2 | 2
4 | x | 3278 | 0 | 0 | 0
5 | y | 3278 | 0 | 1 | 1
2 | e | 3278 | 0 | 2 | 2
(5 rows)
元组的可见性判定
其实对于元组的可见性判定规则,源代码中在函数头上面的注释中都给出了给要义,可以将它们看为精华所在;这一点在理解透之后,就会意识到。
对于不同版本的元组,其可见性的判定规则有好几种,可依据其判定规则适用在不同的场景下。对应规则实现的具体函数逻辑可以参考相应的代码,也可以与《PostgreSQL数据库内核分析》这本书中相关部分给出的流程图进行理解。
HeapTupleSatisfiesMVCC
这个规则主要适用的场景就是对用户表的正常查询,所有从用户发起的、对表数据的查询select语句都会使用这个判定规则。
01020 /*
01021 * HeapTupleSatisfiesMVCC
01022 * True iff heap tuple is valid for the given MVCC snapshot.
01023 *
01024 * Here, we consider the effects of:
01025 * all transactions committed as of the time of the given snapshot
01026 * previous commands of this transaction
01027 *
01028 * Does _not_ include:
01029 * transactions shown as in-progress by the snapshot
01030 * transactions started after the snapshot was taken
01031 * changes made by the current command
01032 *
01033 * This is the same as HeapTupleSatisfiesNow, except that transactions that
01034 * were in progress or as yet unstarted when the snapshot was taken will
01035 * be treated as uncommitted, even if they have committed by now.
01036 *
01037 * (Notice, however, that the tuple status hint bits will be updated on the
01038 * basis of the true state of the transaction, even if we then pretend we
01039 * can't see it.)
01040 */
01041 bool
01042 HeapTupleSatisfiesMVCC(HeapTupleHeader tuple, Snapshot snapshot,
01043 Buffer buffer)
符合以下条件的元组由该规则判定是可见的,
- 生成该快照时刻,所有已提交的事务(修改的元组)
- 该事务的先前命令(修改的元组)
但是不包括
- 该快照中的活跃事务(所修改的元组)
- 取得快照之后方才开始的事务(修改的元组)
- 本事务中本命令中做了修改(的元组)
上面规则判定的详情是在函数HeapTupleSatisfiesMVCC中实现的。
HeapTupleSatisfiesNow
00322 /*
00323 * HeapTupleSatisfiesNow
00324 * True iff heap tuple is valid "now".
00325 *
00326 * Here, we consider the effects of:
00327 * all committed transactions (as of the current instant)
00328 * previous commands of this transaction
00329 *
00330 * Note we do _not_ include changes made by the current command. This
00331 * solves the "Halloween problem" wherein an UPDATE might try to re-update
00332 * its own output tuples, http://en.wikipedia.org/wiki/Halloween_Problem.
00333 *
00352 */
00353 bool
00354 HeapTupleSatisfiesNow(HeapTupleHeader tuple, Snapshot snapshot, Buffer buffer)
符合以下条件的元组对于该规则是可见的,
- 当前时刻所有已提交事务(涉及的元组)
- 本事务前面命令所(更新的元组)
但是不包括符合如下条件的无组
- 本事务中本命令中做了修改(的元组)
上面规则判定的详情是在函数HeapTupleSatisfiesNow中实现的。
HeapTupleSatisfiesSelf
00141 /*
00142 * HeapTupleSatisfiesSelf
00143 * True iff heap tuple is valid "for itself".
00144 *
00145 * Here, we consider the effects of:
00146 * all committed transactions (as of the current instant)
00147 * previous commands of this transaction
00148 * changes made by the current command
00149 *
00150 * Note:
00151 * Assumes heap tuple is valid.
00152 *
00164 */
00165 bool
00166 HeapTupleSatisfiesSelf(HeapTupleHeader tuple, Snapshot snapshot, Buffer buffer)
符合以下条件的元组对于该规则是可见的,
- 当前时刻所有已提交事务(涉及的元组)
- 本事务前面命令所(更新的元组)
- 本事务中本命令中做了修改(的元组)
可以对比一下与NOW规则的区别。上面规则判定的详情是在函数HeapTupleSatisfiesSelf中实现的。
HeapTupleSatisfiesDirty
00830 /*
00831 * HeapTupleSatisfiesDirty
00832 * True iff heap tuple is valid including effects of open transactions.
00833 *
00834 * Here, we consider the effects of:
00835 * all committed and in-progress transactions (as of the current instant)
00836 * previous commands of this transaction
00837 * changes made by the current command
00838 *
00839 * This is essentially like HeapTupleSatisfiesSelf as far as effects of
00840 * the current transaction and committed/aborted xacts are concerned.
00841 * However, we also include the effects of other xacts still in progress.
00842 *
00843 * A special hack is that the passed-in snapshot struct is used as an
00844 * output argument to return the xids of concurrent xacts that affected the
00845 * tuple. snapshot->xmin is set to the tuple's xmin if that is another
00846 * transaction that's still in progress; or to InvalidTransactionId if the
00847 * tuple's xmin is committed good, committed dead, or my own xact. Similarly
00848 * for snapshot->xmax and the tuple's xmax.
00849 */
00850 bool
00851 HeapTupleSatisfiesDirty(HeapTupleHeader tuple, Snapshot snapshot,
00852 Buffer buffer)
符合以下条件的元组对于该规则是可见的,
- 当前时刻所有已提交的事务和活跃事务(所涉及的元组)
- 本事务前面命令(修改的元组)
- 本事务当前命令(修改的元组)
可以再对比一个该规则与上面的规则的区别。上面规则判定的详情是在函数HeapTupleSatisfiesSelf中实现的。
HeapTupleSatisfiesAny
很简单的一种判定规则,即所有元组在这种规则下都是可见的。
其他
还有HeapTupleSatisfiesVacuum + SnapshotToastData + HeapTupleSatisfiesUpdate这三个是没有详细说明的,这可以在后面涉及到vacuum/toast/update的时候进行详细的说明。最后,可以对上面几个规则作一个对比表如下:
| 对比项 | 以生成快照时刻为准 | 以当前时刻为准 | 已提交事务的元组 | 活跃事务的元组 | 包括本事务前面命令的修改 | 包括本事务当前命令的修改 |
|---|---|---|---|---|---|---|
| HeapTupleSatisfiesDirty | N | Y | Y | Y | Y | Y |
| HeapTupleSatisfiesSelf | N | Y | Y | N | Y | Y |
| HeapTupleSatisfiesNow | N | Y | Y | N | Y | N |
| HeapTupleSatisfiesAny | N | N | Y | Y | Y | Y |
| HeapTupleSatisfiesMVCC | Y | N | Y | N | Y | N |
虽然在上面对比中,ANY规则和DIRTY规则的比较显示是一致的,其实二者是不相同的;上面的比较并没有区分insert/delete的效果,是应该看到还是不应该看到。ANY规则是最好容易理解的一种,即所有的元组都是可见的,不论是insert,还是delete,不论这个操作是已完成、已回滚,还是进行中的,一切皆是可见的。
说到MVCC的话,必然不能够绕过两个概念,一个是snapshot(快照),一个是事务隔离级别。那么,这三者之间又是一种什么样的关系呢?下面几篇文章将接着这个话题来说,先会说一下快照与事务隔离级别。
参考
- Postgresql的隐藏系统列
- PostgreSQL Concurrency with MVCC
- PostgreSQL的MVCC实现
- heap tuple header struct
- PostgreSQL的MVCC原理
- 《PostgreSQL数据库内核分析》
修订历史
- 2017.08.04 将元组的可判定性规则同元组的多版本介绍放在同一篇文章中,这样会更合理一些