PostgreSQL之空闲空间管理FSM
堆元组在不停地删除和更新之后,总是会在一个页内留一定的空间;这些空间可以进行复用,使得页扩展得以缓解。这些空间是由vacuum来进行物理回收的,之后进行元组的再插入时,就需要找到一个可以容纳新元组的页。这个功能就是由fsm来实现的。
首先,fsm把一个页由全空的页到全满的页,按空间可用度划分为了256个档次,使用1字节来存储对应的空闲档次。以8KB大小的页来讲,第一个空闲档次大小为32字节。
然后,使用单独fsm堆存储来管理,其文件的命名方式为:mainrelfilenode_fsm.segment, 其中mainrelfilenode为主表的文件的OID标识, fsm是关键标识, segment则每1G大小的文件为一个段。其存储的位置与主件在同一个目录下面(相同的表空间,相同的数据库)。
最后就是关于fsm的实现方式。因为页号用uint32来表示的,每一个页的空闲空间档次是用一个字节来表示的;所有页的空闲空间可用使用最简单的数组方式来管理,这样子存在的一个问题是:当需要找一个空闲空间至少为N档次的页时,就需要顺序遍历所有页来查找这样的一个满足条件的页。 很明显地,这种方式存在的总是是寻找效率的问题。为了解决查询效率的总是,pg使用了分层树 + 大顶堆的方式来实现。实现的主要原理图如下:
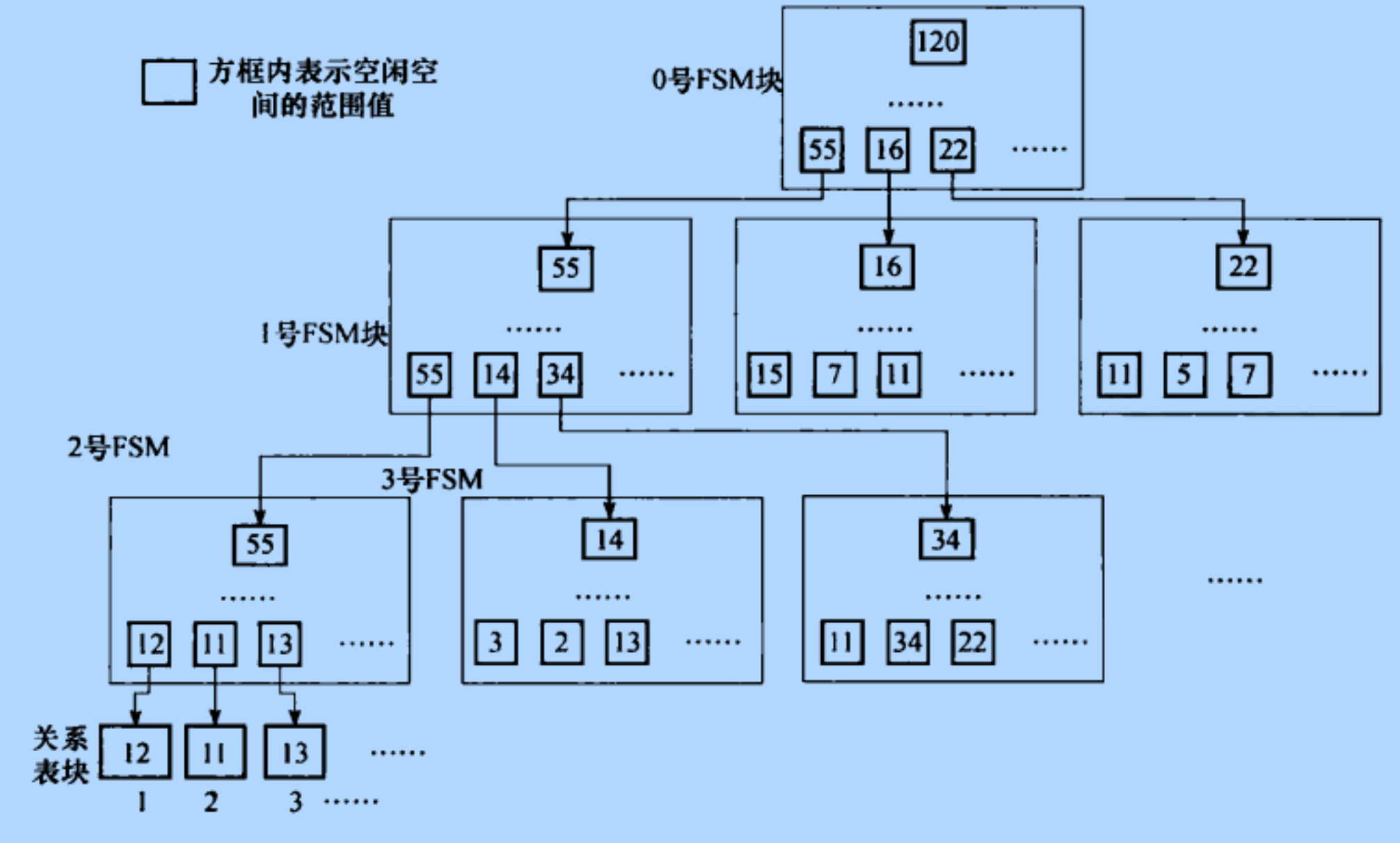
Figure FSM物理块与逻辑地址的映射关系(来自postgresql内核分析一书)
怎么样理解这个图呢?从下向上的方式来理解这个图会更好一些。堆表的页从0开始一直到最大,对应的空闲档次也为元素大小为1字节的、个数与页数相同的数组。要加速搜索,就要使用分组+局部排序+分层排序的方法。
- 首先, 对这个数组进行按固定大小进行分组;例如页的近一半大小,近乎4000.这样,可以分出M=(2^32/4000)个组来。
- 然后,对一个组内的空闲档次使用大顶堆排序;相对于整个集合来讲,这就是一个局部排序。大顶堆的个数为M,即分组个数。这仍然是一个很大的数值,需要再次分层;
- 所有堆的堆顶元素又组成了一个集合,大小为M。再次对这个集合进行分组,每个组的大小仍然为4000,这样可以分出M1=M/4000的小组来;同样,继续对组内的4000个元素使用大顶堆排序;
- M1小组的堆顶元素又可以组成一个集合,如果集合仍然很大的话,可以继续上面的方式进行分组+排序。
每一次的分组+排序就会形成一个层次,直到找到一个适当的层次。对于uint32个页来讲,这个层次高度为3,即恰好等于图中的树高度。
上面所述原理,映射到书本中的描述就是如下:
1. 第2层FSM块中最大堆二叉树的每一个叶子节点表示一个表块的空闲空间值。按照从左至右的顺序,所有第2层FSM块的叶子节点排列起来就一一对应了表文件中的每一个表块。也就是说,最左边的FSM块中左边第一个叶子节点对应表文件的第一块,左边第二个叶子节点对应表文件的第二块,依此类推。
2. 第1层FSM块中的叶子节点从左至右顺序对应第2层FSM块的根节点。
3. 第0层FSM块中的叶子节点从左至右顺序对应第1层FSM块的根节点。
另外一个很明显的问题是,当插入元组影响了对应页的空闲空间大小后,应该怎么去调整堆结构以及三层结构呢? 考虑到性能的问题,pg只调整当前FSM当前块中的大顶堆结构,以及更新对应的页可用空闲空间大小。只有在vacuum的时候,才会去重新建立或者调整整个FSM分层结构。
这种二维树形结构映射到一维的磁盘上,页号的编号顺序与该树的深度遍历序号是相同的。