使用松散同步时钟的高效并发控制
论文题目: Efficient Optimistic Concurrency Control Using Loosely Synchronized Clocks
摘要
论文是在1995年发表的,当时分布式数据系统中怎么实现分布式事务这个方向就是一个热门的领域,这么多年过去了,一直到现在,当时提出的OCC(Optimistic Concurrency Control)仍然是当今的一个热门个研究方向。
人们一直都希望能够实现一个高效、可扩展、稳定的持久化存储系统,而本文提出的OCC正是用来解决这个问题的,其特点是:
- 数据在client端本地缓存,在server端持久化;
- 对提交的事务提供了serializability and external consistency的保证;
- 通过松散同步的时钟获取global serialization;
OCC支持并发事务,但是没有像传统方法那样对每个数据都保存着并发控制的信息,而是只保存了一个版本号,保证了内存消耗尽量的少,并且低存储消耗的情况下,也保证了性能。
介绍
- 本文介绍的OCC适用场景
分布式面向对象数据库系统,数据持久化由server负责,client为了提高性能会对数据进行cache。
- 为什么叫乐观并发控制?
乐观是相对比悲观算法来说的,为了保证事务的external consistency,一个简单的方法就是通过锁,将所有事务串行化,但是这样子肯定会使得性能很差,那解决方法就是去掉锁,只有当冲突发生的时候才采取措施,因此乐观是相对于悲观的加锁算法来说的。
- 什么是external consistency?
external consistency(有些文章叫Linearizability或者strict serializability) 是指:后开始的事务一定可以看到先提交的事务的修改
- 乐观的代价
由于我们不采用锁,因此OCC有其使用的限制:适合冲突少的场景,如果大量事务都发生冲突,那OCC会有非常糟糕的性能,因为:悲观算法只会延迟事务的执行,乐观算法一旦冲突,会直接终止事务执行。本论文之前的最好的OCC算法是adaptive callback locking。
- 乐观的实现
乐观算法本质上只是将冲突的检测延后了,当发生冲突后进行恢复,因此核心解决的问题有两个:冲突检测 ; 冲突恢复 。
环境
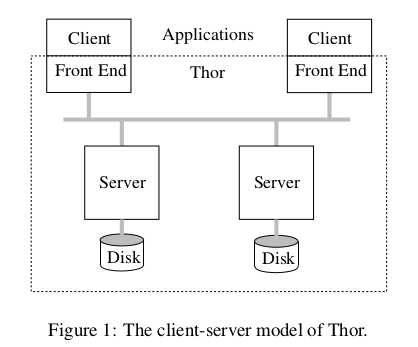
我们的工作是基于Thor数据库进行的。Thor是一个面向对象的数据库,它允许用户程序共享所有的持久化对象。为了安全考虑,对象进行了封装; 用户程序通过接口方法来访问和修改这些共享对象的状态。客户端的计算使用事务进行保护,所以持久化对象可以并发地访问并保证一致性; 所以,客户端的程序有可能执行失败。
应用运行在客户端上,持久化的数据在存储在服务端上。可能有多个server,应用可以通过访问接口来创建新 的持久化对象; 持久化对象会在服务端之间进行发生迁移。持久化对象的创建和迁移都有事务保护。
客户端的特性
- 缓存计算的数据;
- 采用预取方式从服务端获取数据以及可能相关的数据;
- 以上两点在客户端主要由Front End来实现和管理;
服务端特性
- 使用cache set来记录每一个客户端访问的对象集;
- 事务处理;
当客户端最后提交的时候,会搜集所有与事务相关的信息,主要包括了:
- validation information:表示本次事务T中涉及到的数据的读写类型以及对象标识;
- installation information:修改后的数据(副本);
client发送commit请求给后端server,如果这些数据是server自己拥有的,则进行提交操作,否则,server转换为Coordinate角色,和拥有数据的participants一起完整事务的提交操作。
此时coordinate和participants之间会涉及到2-phase protocol,主要过程如上图所示。这个过程主要有两个阶段:
第一阶段如下:
- coordinate发送prepare message给各个参与者,消息包含了validation information和installation information两部分数据;
- 参与者尝试进行检查;验证通过后,将 installation information记录到磁盘,回复ok给coordinate;
- coordinate收到所有参与者回复ok后,记录一条commit消息到本地磁盘,然后回复给客户端说ok;
第二阶段是异步执行的
- coordinate发送commit消息给各个参与者;
- 参与者将installation消息中的新值覆盖掉老值(这样子后续的预取就可以看到这些更新了),并在本地记录一条commit日志,回复给coordinate说ok;
当server提交了事务后,需要发送invalidation messages给除了客户端之外的其他持有缓存数据的客户端,那怎么找到这些客户端呢?server这边对每个客户端都存着一个cached set,这些invalidation messages不要求正确,但是需要满足下面两点:
- 如果client收到invalidation messages,当前执行中的transaction还没读到旧数据了,那将本地cache中的数据失效
- 如果当前transaction已经读到旧数据了,则立即终止当前transaction
当客户端处理完invalidation messages消息后,回复给server,server将其从失效集合(invalid set)中移除。
高效的验证规则
算法保证了两种一致性:
- Serializability:所有提交的事务都可以排个序,实际执行的效果跟按照这个序依次执行事务一致
- External consistency:后开始的事务一定可以看到先提交的事务的修改 验证发生在一个事务请求提交的时候,验证分两种:
- Forward validation:和所有正在执行的事务进行冲突检查
- Backward validation:和所有已经验证成功的(validated)事务进行冲突检查
本论文中采用的是第二种验证方法。
全局序
全局序是通过每台机器上的时间戳来获取的,但是每个机器的时钟会存在不同步,因此会带来一些偏差,于是谷歌的[Spanner][2]通过在数据中心配备原子钟和GPS接收器来解决这个误差范围不确定的问题,进而解决分布式事务时序这个问题,本文提出的算法假设是这种时钟不一致时可控的。
在coordinate收到commit请求后,会读取本地时钟的时间戳,并赋值给事务T.ts,coordinate发送给参与者的prepare msg包含:
- T.ts:事务T的时间戳
- T.ReadSet:T读到数据的IDs
- T.WriteSet:T写数据的IDs
- T运行的客户端id 此处T.ts = < timestamp,server-id >
为了简化我们的算法,我们将读集合作为了写集合的一个超集,即写操作之前会将对象定入到读集合中去。参与者会把成功校验过的事务的校给信息使用validation queue(VQ)记录起来。对于要校验的事务,把它与VQ中的记录进行对比来决定是否有冲突,从而来确保外部一致性。
检查ts靠后的事务
考虑场景:S是一个已经验证通过的事务,而此时来了T要求验证,根据T和S的时间戳顺序,会有不同的验证规则,我们先看S的时间戳晚于T。
此处为什么会出现S的时间戳晚,但是反而先提交了呢?这可能就是因为不同机器之间的时钟不同步的原因了。对于这种情况,我们检查规则是:
对于每个已经验证通过,并且时间戳大于T的事务,我们检查T没有读取任何S修改过的数据,也没有更新任何S读取的数据。我们称这种检查为:later-conflict检查
检查ts靠前的事务
对于已经验证通过的而且时间戳早于T的事务S,我们考虑:
- S读取了x,T修改了x,此时我们没必要检查
- S修改了x,T读取了x,此时我们需要保证T读取到的时候修改后的x,此时又分为两种情况
- 如果S还没有提交了,那中断T,因为T不可能读取到还没提交的数据
- 如果S已经提交了,此时取决于T读取到的x的version了
下面具体说下version-check。为了要实现version-check,一般的做法是给每一个object关联一个version,这个version可以是每次提交写操作事务的时间戳,满足了单调递增的需求,但是这样会造成不必要的空间浪费,于是本文提供了一种叫 current-verison-check 的方法:
检查T已经读到了x的最新值
具体是怎么做到的呢?我们先来简单论证下current-verison-check和version-check是一致的,假设T读取了x,并且已经过了later-conflict检查,说明在T之后已经验证通过的事务没有更新x的了,如果此时T通过了version-check,说明T读到x是之前更改过x之后最新的值,那此时T读到的x当然是最新的,是当前版本。
我们的server对每个client都保存了一个invalid set,用于保存客户端已经失效掉的、曾存在于cache set中的对象。当front end接收到失效消息之后,它丢弃掉其缓存中的对象列表; 如果当前事务使用了缓存中的任何一个对象,立即回滚事务,然后给server发送一个确认的消息。一旦接收到确认的消息,server将对应客户端的中invalid set中的对象移除掉。也正是如此,invalid set可以一直维持着比较小的空间。
此时我们只要去看下T读到的x是否在client的invalid set之中,就可以知道x是否是最新的了。 使用失效集合的列子:
Client C2:
T2 ... Rx ... client/TC about to send out prepare msgs
Server:
T1 wrote x, validated, committed
x in C2's invalid set on S
server has sent invalidation message to C2
server is waiting for ack from C2
3个cases:
- inval消息在C2发送prepare消息前到达C2
- C2 aborts T2
- inval在C2发送完prepare后,等待 yes/no的回答时
- C2 aborts T2
- inval丢失或者延迟了(so C2 doesn’t know to abort T2)
- S没有收到C2的ack
- C2还在S上的x的inval set
- S会对T2的prepare消息回复说no
通过上面的分析,如果此时进行current-verison-check的时候,x不在invalidate set中,那client肯定是已经收到x过期的消息了,如果此时x的值不是最新的,那肯定是在上面3个case中的case2中,即在发送prepare消息后,此时即使server回复ok了,事务也终止了,没什么问题。
本节sever上需要有个内存中的数据:
- cached sets
- invalid sets
- VQ
其中前两个都不大,但是VQ如果不清除的话,会越来越大,下节就介绍怎么对VQ进行截断。
截断(Truncation)
VQ中存储着所有验证通过的事务,如果我们不去清理,会越来越长,那我们清理应该清理掉哪些事务呢?
-
已经提交了的事务
由于invalid set中保存着已提交事务的影响,所以可以删除
-
只读的事务
对于已经移除的只读事务,我们怎么知道它读到了什么数据呢?我们维持了一个threshold timestamp,这个threshold大于等于所有已经从VQ中移除的transaction的时间戳。
我们在整个过程中,维持着下面的不变量:
VQ中保存着所有未提交的read-write事务,以及所有大于threshold的事务
于是有了threshold check,所有小于threshold的都验证失败,因为没有足够的信息来进行later-conflict,而通过threshold check的检查,会有足够信息来进行earlier check。
那有了threshold的概念,那怎么设置呢?设置的太高,会导致事务在检查threshold check就失败,设置的太低,会导致VQ队列太长。
我们假设消息的传输延迟是msg delay,而时钟时间的误差是skew,则当消息从coordinate发出到达到participant这个延迟是:msg delay + skew,那如果此时participant的时间是t1,则有可能已经发出,但是未到的事务的时间 t 应该是 t > t1 - (msg delay + skew),我们将msg delay + skew称之为Threshold Interval。
此时我们总结下我们目前所有的验证规则是:
- Threshold Check
- 所有小于Threshold都失败
- Checks Against Earlier Transactions
- 对于VQ中未提交的,时间戳小于T的事务S,如果T中有读取到了S中写的数据,返回失败
- Current-Version Check
- 对于T中每个读的数据x,如果x在invalid set中,则返回失败
- Checks Against Later Transactions
- 对于VQ中时间戳大于T的事务S,只要T中读的数据在S中被修改了,或者T中写的数据在S中被读取了,都返回失败
崩溃后的恢复
当server从崩溃中恢复过来后,需要保证在崩溃前验证的事务要保证和恢复后验证的事务还是满足验证规则,因此一个自然的想法就是将VQ和Threshold记录到磁盘上。
对于读写事务,在prepare的时候,本来就需要记录installation信息,此时记录VQ不会带来额外的开销,但是对于只读事务,在prepare的时候,是不需要记录installation,如果此时记录VQ,会带来性能的损耗,因此我们的做法是不进行记录。
如果我们对只读的事务不进行记录,那当crash后恢复,则会丢失这部分信息,但是如果我们将Threshold设置为大于服务器上最后一个验证通过的事务,那就不担心只读数据的丢失了。
另外cached set也没有进行持久化存储,作为替代的,server存储了cache着数据的client地址。crash恢复后,server和client进行通信,进行cached set的恢复。
最后Invalid set通过记录的installation info和cached set进行恢复,但是这可能由于丢失client的ack,而多出一些不必要的项。怎么解决呢?当一个事务引发invalidation msg的时候,server会产生一个invalidation number,和提交日志一起存储,而且invalidation number保证单调递增,当发送invalidation msg的时候,会将invalidation number带上,此时client在收到后将invalidation number存储起来,当恢复的时候,客户端会将invalidation number和cached set一起带过来,server就能依据invalidation number来重建正确的Invalid set了。
模拟实验
TODO: 补充
总结
- caching减少了client/servr之间的数据fetch,所以快
- 分布式OCC避免了clien/server的锁争用
- 松散的时间同步帮助servers对顺序达成一致,达到检测的目的
- 分布式OCC在20年后仍然是一个热门领域
参考
- 大部分内容来自于简书高效的并发控制
- Fine-Graned Sharing in a Page Server OODBMS 1994年