Kudu:在快速数据上快速分析的存储
论文题目: Kudu:storage for fast analytics on fast data 快速下载
论文时间: 2015.09.28
作者: Cloudera公司的一批大佬

[1]Kudu,对应中文的含义应该是非洲的一种带条纹的大羚羊。 Cloudera则给自己新开发的大数据存储系统命名为Kudu,应该代表了Kudu速度快是一大特点。 在Cloudera官方的博客上,对于Kudu的描述是:一个弥补HDFS和HBase之间的缺口的新型的存储,它能够更有效的利用现代硬件的CPU和IO资源,既能够支持分析,又能够支持更新、删除和实时查询。
摘要
Kudu是为结构化数据设计的开源存储引擎,它同时支持低延时的随机访问和高效分析的访问模式。Kudu使用水平分隔对数据进行分布,并且使用Raft来repliicate每一个分区,提供低平均恢复时长(low mean-time-to-recovery)和低尾延时(low tail latencies)。它主要处于Hadoop生态系统中,也支持Cloudera Impala, Spark, MapReduce等工具的访问。
1. 介绍
在Hadoop生态中,结构化存储有两种典型的实现方法:
- 静态数据集,
- 二进制方式存储在HDFS中(Apache Avro/Parquet)
- 欠缺考虑记录的更新,或高效地随机访问
- 可变数据集,
- 半结构化地存储在Apache HBase/Cassandra中
- 考虑了记录级别的低延时读和写,但在顺序读上不如前者,不利用AP场景
静态数据在HDFS上提供的分析性能与HBase和Cassandra提供的行级高效随机访问能力之间存储一条鸿沟。正因为如此,实际中的Cloudera用户构建了比较复杂的架构系统来进行存储和分析。
[1]说到开发Kudu的初衷,Cloudera的解释是他们在客户的现场做大数据项目时发现,真正客户面临的问题在当前的Hadoop生态系统下,都是一个混合的架构,如下图所示:
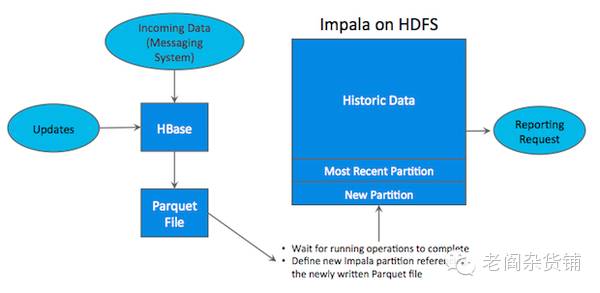
在这个架构中,HBase被用来当作数据载入和更新的存储,这个存储适合于实时的查询,而数据随后被处理为parquet格式的文件,从而适合后续的利用Impala等工具进行分析。
以上构架存在主要的问题是:
- 应用架构必须写复杂的代码来管理两个系统间的数据流和数据同步问题;
- 运维者必须管理一致性的备份,安全策略,以及多个系统的监控;
- 在新数据到达HBase和可对新数据进行分析之间的延时较大;
- 把后来数据迁移到不变的存储集中,需要进行昂贵的重写、交换、分区和手动变换。
而Kudu则主要针对这个混合架构的需求所设计开发的一个存储系统,希望能够降低这种混合架构系统的复杂性,同时能够满足客户类似的需求。
Kudu的设计目标:
- 对于scan和随机访问都有非常好的性能,从而降低客户构造混合架构的复杂度
- 很高的CPU利用效率,从而提高用户在现代CPU使用上的投入产出比
- 很高的IO利用效率,从而更好的使用现代的存储
- 能够对数据根据数据所在位置进行更新,从而减少额外的处理和数据的移动
- 支持多数据中心的双活集群复制
Kudu在Hadoop生态系统中所处的角色和位置如下图所示。
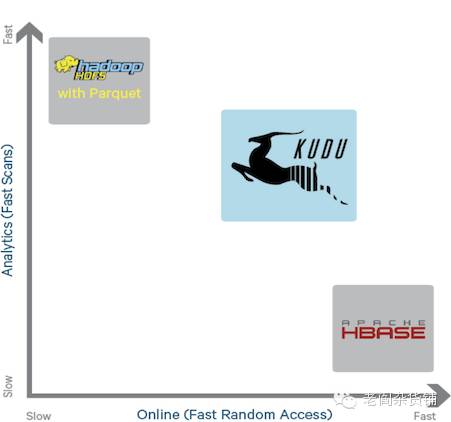
高层次看Kudu
表和schemas
从使用者的角度来看,kudu是以表的形式进行结构数据存储的存储系统。一个kudu集群有多个表,每个表都是由shema进行定义,包含有限个列,每列有一个名字和类型,并且可以选择是否支持空值。这些列的一些有序的列可以定义为表的主键,主键有唯一性约束,并且作为删除和更新的索引。这些特性与传统的关系型数据库非常的相似,但是与Cassandra,mongodb,riak,bigtable等分布式数据存储却非常的不同。
与使用关系型数据库一样,kudu的用户必须要先在创建表时给定表的schema,如果插入不存在的列会报错,并且违反唯一性约束也会有相应的错误。用户可以通过alter table来增加或者删除列,但是主键列不能够被删除。
NoSQL的思想是,一切都是字节。我们不采取这个NoSQL的方法而是显式地声明列类型,主要是以下两个因素:
- 与采取与类型相关的encoding
- 允许我们将类似SQL的元数据导出到其他的系统中,例如BI或者数据挖掘工具
不过Kudu的设计不支持二级索引,这个限制和HBase是一样的; 也不支持除主键外的唯一性约束。另外,当前的kudu要求每一个表必须定义一个主键列。
写操作
对于kudu的写操作来说,insert,update,delete都必须指定主键才能进行。另外也和HBase一样,kudu不支持跨行级别的事务(multi-row transactional );也就是说,理论上每一个改动都是在它自己的事务内执行。
Kudu当前提供的主要接口是JAVA和C++,当前python还是实验性支持。
读操作
对于读来讲,kudu只提供了一个scan操作来从表读取数据,不过用户可以给定一些条件来过滤结果(谓词条件)。Kudu的客户端API和服务端都会对谓词条件进行解释,以此来砍掉大量的不需要从磁盘读取、或从网络传输的数据。目前kudu支持两种条件比较:
- 列和常量进行比较
- 给定主键的范围
对于kudu的查询来讲,用户还可以限定只返回部分列(投影操作),因为Kudu的实际存储是列式的存储,这种限定可以大幅度的提高性能。
其他API
Kudu客户端库还提供了别的有用功能。特别地,Hadoop生态系统可通过数据位置(data location)的调度来获得更好的性能。 Kudu提供的API可让客户来确定数据范围到服务器的映射,从而辅助分布式执行框架(像Spark, MapReduce, Impala)的调度。
一致性模型
Kudu给客户提供了两种一致性模型:
-
默认是快照一致性,保证 read-your-writes 的一致性
默认情况下,Kudu并不提供external consistency的保证。举个简单的例子
- client1 –> 进行写 r1
- client1 –message bus–> 与client2进行通信
- client2 –> 进行写 r2
- reader 结果看到了client2写的结果却没有看到client1写的结果
reader无法捕捉到client1和client2之间的因果信赖关系。这在大多数的情况下,用户是可接受的,OK的。
-
时间戳
执行写后,用户向客户端库要一个时间戳;这个时间戳会通过外部管道扩散到其他的客户端,这样就可以阻止跨越两个客户端的、之间有因果树信赖关系的写了。
如果这个扩散过程太复杂的话,Kudu可选commit-wait方式(与Spanner一样)。在这种方式下,客户会被延一段时间,以保证后来的写可正确地因果有序。 这样子的话,是需要NTP的支持,或者是高精度的全局时间同步。
时间戳的赋值是基于clock算法的,称为HybridTime,可以参考末尾的引用文章。
时间戳
Kudu内部使用时间戳来实现并发控制,它不允许用户手动设定一个写操作的时间戳。主要是因为只有高级用户才会有效地使用时间戳,而这部分用户是少量的; 对于大多数用户来讲,这个高级特性令他们是迷惑的。
对于写来讲,Kudu允许用户指定一个时间戳。这样,用户就可以执行point-in-time查询(过去的一个查询); 同时,Kudu保证构成一个简单查询(像在Spark或Impala)的不同的分布式任务读取使用了同一个一致性快照。
架构
Kudu 有两种类型的组件, Master Server 和 Tablet Server 。 Master 负责管理元数据。这些元数据包括 talbet 的基本信息,位置信息。 Master 还作为负载均衡服务器,监听 Tablet Server 的健康状态。对于副本数过低的 Tablet , Master 会在起 replication 任务来提高其副本数。 Master 的所有信息都在内存中 cache ,因此速度非常快。每次查询都在百毫秒级别。 Kudu 支持多个 Master ,不过只有一个 active Master ,其余只是作为灾备,不提供服务。
ablet Server 上存了 10~100 个 Tablets ,每个 Tablet 有 3 (或 5 )个副本存放在不同的 Tablet Server 上,每个 Tablet 同时只有一个 leader 副本,这个副本对用户提供修改操作,然后将修改结果同步给 follower 。 Follower 只提供读服务,不提供修改服务。副本之间使用 raft 协议来实现 High Availability ,当 leader 所在的节点发生故障时, followers 会重新选举 leader 。根据官方的数据,其 MTTR 约为 5 秒,对 client 端几乎没有影响。 Raft 协议的另一个作用是实现 Consistency 。 Client 对 leader 的修改操作,需要同步到 N/2+1 个节点上,该操作才算成功。

Cluster角色
kudu的集群架构与HDFS,HBase架构类似,Kudu有一个Master Server负责元数据的管理,多个Tablet Server负责数据的存储。Master Server可以通过复制来是先容错和故障恢复。
分区
与大部分的分布式数据库系统一样,kudu的表是水平分区的,这些水平分区的表叫做tablets。每一行都会根据它的主键唯一的映射到一个tablet上。对于吞吐量要求比较高的情况下,一个大表可以分为10到100个tablets,每个tablet差不多可以是10G大小。
至于partition的方式,Kudu支持在创建表时给定一个partition schema,这个partition schema是由0个或者多个hash分区规则以及一个可选的范围分区规则组成。
-
hash分区规则由主键列的子集列和分区bucket数量构成,例如:
DISTRIBUTE BY HASH(hostname, ts) INTO 16 BUCKETS 这个规则基本是采用拼接需要hash的列,对桶数求余,然后生成一个32位的整形作为结果的分区key。
-
范围分区规则则是基于有序的主键列,将列的值按照能够保持顺序的编码进行处理,然后将数据进行相应的分区。
正是提供了这些分区规则,用户可以基于他们的负载来平衡查询并行和查询并发。比方说,考虑一个时间序的应用,它存储了这样的记录(host, metric, time, value), 并且该应用总是插入单调递增的 time 值。选择对时间戳进行hash分区,可以把插入负载分散到所有的服务端; 但是,对 host 的小时间范围内的查询就必须扫描所有的表,这就限制了并发度。 用户可能会为时间戳选择范围分区,再加上 metric 和 host 选择hash分区,这样就可以提供写并行和读并发的平衡。
尽管说使用者必须理解分区的概念才能够优化使用Kudu,但是分区键编码却对用户是完全透明的。用户需要指定的是rows, partition split points, key ranges。这一点对于SQL用户来说是相当熟悉的。
replication复制
Kudu采用了Raft协议来实现表数据的复制,在具体的实现过程中,Kudu对于Raft协议也做了一些修改和增强,具体的表现在:
- 在Leader选举失败时,采用指数算法(Exponential Backoff)来重试。
- 当一个新的leader在联系一个follower时,如果follower的log与自己不相同,kudu会立即跳回到最后的committedIndex,这能够大大减少在网络上传输的冗余的操作,而且实现起来简单,并且能够保证不一致的操作在一次往返后就被抛弃掉。
另外,kudu的复制不是复制磁盘上的存储的表的数据,而是复制操作日志。表的每个副本的物理存储是完全解耦的,它带来了如下的好处:
- 当一个副本在进行后台的一些物理层的操作(flush或者compact)时,一般其他节点不会同时对同一个tablet做同样的操作,因为Raft协议的提交是过半数副本应答,这样后台物理层操作对于提交的影响将会降低。TODO:我们期望在不久的将来可以实现论文[16]所描述的技术,从而在读写并发负载中降低读的tail latencies(尾延时)问题。
- 在开发过程中,kudu团队遇到过一些罕见的物理存储层race condition情况,因为物理存储的松耦合,这些race condition都没有造成数据的丢失。在所有情况下,我们都可以检测到某个副本已经损坏,然后修复它。
配置变化
Kudu通过one-by-one算法来实现Raft配置变更。 在这种方法里,每一次配置变化中最多涉及一个投票者数目的变化。那么,从3个replica增长为5个replica的话,就需要进行两次独立的变更,首先是从3到4,再是从4到5。
Kudu是使用 remote bootstrap这种方式来新增一个server的。在我们的设计里,要新增一个replica的话,首先将它新增为配置中的一员,然后通知目标server说将会有一个新增的replica要去复制它。 in details
- 完成第一步
- 当前的leader就会触发一个 StartRemoteBootstrap RPC,目标server就会从当前leader上拉一个快照的tablet数据和日志,直接所有传输都完成
- 新增server按照正常restart过程一样,打开tablet
- tablet打开它的数据,replay它的WAL日志,
- 新增server回复leader一个Raft RPC,表明自己达到了 full-functional replica状态
实现的时候,新增server是以 VOTER 角色立即加入的。这会有一个缺陷是,配置从3谈到4时,四分之三的server必须确认每一个操作。因为新增server还在复制过程中,它不能够确认操作。 如果另一个server发生了crash的话, tablet就可能变得写不可用,一直到 remote bootstrap结束。
要解决这个问题,我们计划引入一个新的状态为 PRE_VOTE ,在这个状态中新增server是不作为投票者之内的。只有当新增server完成了以上5步之后,当前leader方才会删除 PRE_VOTE 状态记录,并进行另一个配置更改,将新增server作为一个正式的 VOTER 存在。
Kudu Master
前面提到了Kudu的集群架构,具体到Kudu的Master进程,它主要的职责包括:
- 它是一个catalog manager,维护table, tablets的信息,以及创建table的schema,复制的级别以及其他的一些元数据。 当对表进行创建、修改、删除时,Master需要跨tablets协调这些动作,保证它们最终的完整性。
- 它是集群的协调者,跟踪集群中server的存活状态以及在某个server死掉后对数据进行重新分布。
- 它是一个tablet directory,跟踪那个tablet server存储哪个tablet的副本。
我们选择了一个中心化的、可复制的master设计,主要考虑了实现、调试和操作的简单性。
元数据的管理者
master上有一个特殊表用于存储catalog信息,
- 这个表是不允许用户直接访问的
- keep a full write through cache of the catalog in memory at all times 对内存中的元信息总是使用直写缓存
假定硬件的内存是很大的,而每个表的元数据是很小的,我们并不希望元数据的管理在将来成为了一个问题。如果确定成为问题的话,修改为page cache实现应该会是框架上的一个直接的革新。
catalog表维护着系统中的每一个表的所有状态。特别是,它保存着表定义的当前版本,表的当前状态(创建,运行,删除,等等), 组成表的tablets集合。 当master要求创建一个新表时,它首先向catalog表中写一个表记录,表示一个 CREATING 状态。异步地,master会选择tablet服务器来存放tablet replicas,创建master端的tablet元信息,发送一个异步请求要tablet服务器新建replicas。
- 如果在多数节点上,replica创建失败或者超时的话,tablet能够安全地删除掉。
- 如果失败发生在中间的话,catalog表中的记录状态将说明需要前滚,master需要从失败的地方恢复重做。
表定义的更改和删除这些操作同样使用相同的方法。master要确保这些修改能够扩散到相关的tablets服务器,然后才能够将它的新状态写入到自己的存储介质上。在所有情况下,从master发送往tablets服务器的消息必须设计为幂等的,所以crash或者重启的话,它们也能够安全地重新发送到其他tablet服务端。
因为catalog表自身也是在Kudu进行持久化的,master可以使用Raft将其持久状态复制到master备上。当前,这些master备只是作为Raft的跟着者(follower),并不会直接响应客户端的请求。由于依赖于Raft的选举算法,master备升主时,与主重启过程是一样的,扫描自己的catalog表,加载自己的内存cache,以活主方式启动了。
集群的协调者
每一个tablet server都在master里都静态地配置成一个host name列表。 启动的时候,tablet server向master注册,发送一个tablet reports来说明它上面的所有tablet集。一开始,这个tablet reports是关于所有tablets的信息。后续的tablet report则是增量的,仅需要包含那些新加的、删除的、修改的tablet。
一个重要的设计点是,当master为作catalog信息的可信源时,它也只是作为一个观察者的身份存在,观察集群的动态变化。tablet server则总是带权威性的,包括了tablet replicas的位置、当前Raft配置、tablet的当前定义版本,等等。因为所有的tablet replica是使用Raft来达到状态变化一致的,所有的更改都会映射到到一条专门的Raft操作上。这便利master可以确信:所有的状态更新都是幂等的,它只需要简单地进行比较操作。如果发现变更版本还不如它自己本身版本的更新,它就会直接丢弃掉这个变更。
TODO:此部分首先要看一下Raft算法的实现。
tablets目录
为了读写的高效性, 客户端在向服务端查询tablet的位置信息后, 会在本地进行缓存处理。 缓存的信息包括了分区键范围和它的Raft配置。 如果客户端信息过期的话,而与它联系的服务端已不再是一个leader的话,
- 客户端向服务端发送一个写操作,该服务端拒绝该请求
- 客户端联系master询问谁是新的leader, master告诉它新leader是谁
上面的第2步是的信息是可以合并的,通过piggy-back(背包)方式直接一次交互完成。
因为master在内存中维护着所有tablet分区范围的信息,就需要考虑是否为请求服务数目scale的问题。如果这部分一旦成为瓶颈的话,我们注意到位置信息即使过期也是安全的,所以就可以对这一部分也进行分区和复制到多个机器上,从而解决scale的问题。
tablet存储
在tablet server上,每个tablet副本都做为一个完全独立的实体,从而与上层的分布式系统和分区进行解耦。
也正是这种解耦,我们可以实现在存储层的过滤,包括: per-table, per-tablet, per-replica。
简述
在Kudu的tablet存储设计中,主要考虑如下几个因素:
- 快速的列扫描,能够达到可以媲美Parquet和ORCFile的类似的性能,从而可以支撑分析业务。主要是大部分的扫描是基于高效编码的列数据文件;
- 低延时的随机更新,在随机访问时,希望达到Olog(n)的时间复杂度
- 性能的一致性,用户更期望在峰值性能和可预期性能之间达到权衡
RowSets
为了达到这个目的,Kudu从头设计了一个全新的混合列式存储架构。在这个新的存储架构中,引入了一个存储单元RowSets,每个tablets都是由多个RowSets组成,Rowsets分为内存中的MemRowSets和磁盘的DiskRowSets。任何一条存活的数据记录都只属于一个RowSet。所以,RowSets形成了行的不相交集。然而要注意的是,不同RowSets的主键范围是可能相交的。
在任意时刻,每个tablet都只有一个唯一的MemRowSets,用于存储最近插入的行。有一个后台线程定期会flush MemRowSets到磁盘,当MemRowSets被flush时,一个新的空的MemRowSets会被创建来替换它,而被flush的MemRowSets则会变成一个或者多个DiskRowSets。Flush过程是完全并行的,对正在flush的MemRowSets的读操作还会在MemRowsets上进行,而更新和删除操作则会被记录下来,在flush完成后更新到磁盘上。
MemRowSet的实现
MemRowSets的实现是一个支持并发的内存B-Tree,借鉴了MassTree的实现,并且做了一些修改:
- 不支持在树上进行元素的删除,而是采用MVCC记录删除的信息。因为MemRowSets最终会flush到磁盘,因此记录的删除可以推迟到flush的过程中。
- 不支持在树上对元素的任意的修改,而只是在值的修改不改变值占用的空间大小时才支持。
- 叶子节点的连接是通过一个next指针来实现,这样可以显著提高顺序scan的性能。
- 为了提高随机访问的scan的性能,采用了比较大的节点的空间大小,每个是4个CPU cache-lines的大小(256字节)
- 使用SSE2预取指令集以及LLVM编译优化来提高树的访问性能
MemRowSets是以行宽度来存储记录的。因为数据总是在内存中,所以它可以提供可接受的性能。
为了形成插入到B树中的key,我们使用前面所述的方法对记录的主键进行保序编码,这样树的遍历就可以通过简单的memcmp操作进行比较。
DiskRowSet的实现
DiskRowSets的实现同样做了很多实现的优化来提高性能,包括:
每达到一个32MB的IO块后,向前滚动DiskRowSet.这样确保DiskRowSet不会太大,允许进行增量地压缩。因为MemRowSet是有序的,所以下盘后的DiskRowSet也是有序的,每一个滚动的段(segment)的主键都是没有交集的。
DiskRowSets在实现时被分成了两个部分,一个基础的数据部分(base data)以及一个变化存储(delta stores)。
- Base data是采用列式存储来存储数据,每一列被切分成一个连续的数据块写到磁盘,并且分成小的页来支持更细粒度的随机访问。它还包含一个内嵌的B-Tree索引,从而方便定位页。
- base data的存储支持bzip2,gzip,LZ4的压缩。
除了每列数据会flush到磁盘,Kudu还在磁盘写入了一个主键索引列,存储了每一行的主键编码,同时还写了一个布隆过滤器到磁盘,从而方便判断一行是否存在。
因为列式存储的数据不容易更新,所以base data在写到磁盘后就不会再改变,变化的值都是通过delta stores来进行存储。delta stores通过在内存的DeltaMemStores和磁盘上的DeltaFiles来实现。DeltaMemStore也是一个支持并发的B-Tree。DeltaFiles是一个二进制的列式数据块。delta stores包含了列数据的所有的变化,维护了一个从(row_offset,timestamp)数组到RowChangeList记录的映射。
Delta Flushes
DeltaMemStore是基于内存的存储,空间有限。相同的后台线程(调度MemRowSets写盘的线程)也会调度DeltaMemStore的周期写盘。当DeltaMemStore写盘之后,一个新的DeltaFile就会生成。一个DeltaFile就是一个简单的二进制列数据文件。
INSERT路径
与NoSQL不一样,Kudu的INSERT与UPSERT是不一样的。每一个tablet都有一个MemRowSet来存储最新插入的数据;然而,空间是有限的,不可能所有的写都直接放入到MemRowSet中来,而Kudu又要求主键遵守唯一性约束。
要强制遵循唯一性约束的话, Kudu就需要在插入数据之前检查磁盘上DiskRowSets中的数据,那么这个效率要求就相当重要了。
-
每一个DiskRowSet都存储了这个集合中关于主键的bloom filter信息。因为新键不可能插入到已有范围内的主键内,所以bloom filter数据就是静态的数据。 以4KB个页为一个chunk,并使用有B-tree对这一个chunk页进行索引。这些页以及它们的索引都使用SLRU缓存进行管理。
-
每一个DiskRowSet还存储了主键的min/max值,并对这些min/max值进行interval tree索引 。
采用上面两种方式可以砍掉好多不需要的DiskRowSet scan。对于那些无法砍掉的,就只能使用搜索 的方式进行。对于主键列,还有一个B-tree索引可以使用在最坏的情况下进行扫描。同样,这部分的数据访问也是通过页缓存进行的,来保证一个键空间的热访问。
READ路径
Kudu的读数据是批量的。其内存格式由是一个top level结构体,里边包含了指向每个要读的列的小块的指针。这相当于也是列格式的,当从磁盘上读取并复制到内存时,避免了偏移量的计算代价。当从DiskRowSet中读取数据时,
- 首先会看扫描所使用的范围谓词是否可以用来砍掉里边的一部分列。
- 接着,一次对一列进行扫描
- 找到目标列的正常行偏移位置
- 对目标列中的cel decode,并复制到内存的batch中
- 到delta存储中查看是否有符合当前MVCC快照的新版本cell,有的话进行替换
- 将batch结果返回给客户端
- tablet服务端会维护着一个迭代的状态,以保证后续的next操作可以继续执行
延时物化
Kudu存储的实现对于列数据采用Lazy Materializtion从而提高读取的性能。
Delta Compaction
因为变化存在delta stores中,而如果delta store数据非常多,则会发生性能问题。Kudu有后台线程会定期根据delta stores的大小来进行压缩,将变化写回到base data中。
主要是估算一个比例,即base data中记录数目与delta中的记录数目的比值。
当进行回写时,主要是针对列的子集。例如,一个更新操作只批量更新了表中的单个列,那么回写也只针对这一个单列进行,以避免不必要的IO操作。
RowSet Compaction
除了delta store的压缩,RowSet也会定期做压缩,通过RowSet压缩,将不同的DiskRowSets合并为一个RowSet(主要是基于键合并key-merge,并保证其合并后有序), 可以实现:
- 移除删掉的行
- 通过基于key的合并,减少同样key范围DiskRowSets的数量。
调度管理
Kudu的后台维护操作是由一个线程池进行管理的,它们是一直运行着的。当某一个维护操作完成后,一个调度进程会评估磁盘存储的状态,再选择下一个操作来平衡 内存使用、WAL获取以及将来的读写性能。
由于维护线程总是远行着小单位的工作,所以可以快速地对当前的工作负载做出调整反应。比方说, 写入负载升高时,调度器将快速反应将内存数据写入到磁盘中。当写入负载减少时,后台可以开始执行compact来提高将来写的性能。
与Hadoop的集成
MapR + Spark
Kudu提供对Hadoop Input和Output数据的binding,从而可以方便的与Hadoop MapReduce集成。这个binding同样可以方便的与Spark集成,一个小胶水层可以将Kudu表bind为Spark的DataFrame或者Spark SQL的table。通过这个集成,Spark可以支持Kudu的几个关键的特性:
- 数据本地性 – 能够知道表的数据在哪个tablet server上,从而支持本地数据处理和计算
- 列规划 – 提供了一个简单的API使用户可以选择哪些列是他们的任务中需要的,从而减少IO读取
- 委托下沉 – 提供一个简单的API去指定数据在被传递给任务时可以在服务端进行计算,从而提高性能。
Impala
性能评估
与Parquet的比较
与Phoenix的比较
随机访问的性能
使用案例
小米是 Hbase 的重度用户,他们每天有约 50 亿条用户记录。小米目前使用的也是 HDFS + HBase 这样的混合架构。可见该流水线相对比较复杂,其数据存储分为 SequenceFile , Hbase 和 Parquet 。

在使用 Kudu 以后, Kudu 作为统一的数据仓库,可以同时支持离线分析和实时交互分析。
