PostgreSQL之高速缓存
pg的内存部分,本地高速缓存是一个绕不过去的话题。它主要包括了两个部分:Catalog Cache; Relation Cache。理解二者的关键信息有:
- Catalog Cache主要缓存了最近使用过的系统表的元组。
- Relation Cache主要缓存了最近使用过的表的模式(schema信息),主要包括了表约束、列约束以及列的定义信息等。
- 系统表本身也是有schema的,它的信息也会缓存在relation cache中。
- Relation Cache相关的主要数据结构体是RelationData,这个结构体的信息是从pg_class、pg_type、pg_attribute、pg_proc、pg_constraint等这些系统表中的元组抽取出来的、组合而成的表信息;
总体来讲,其实高速缓存主要是给系统表(数据字典)的数据的快速访问提供了独立的读缓存 。普通的用户数据则是使用shared buffer进行读写缓存的,当然系统表数据(数据字典)的写缓存也是放在shared buffer的。
Catalog Cache
catcache的总体思想还是哈希;它并没有使用通用的哈希表,而是自己使用链表 + 数组的方式重新构造了自己独特的哈希表。这个读缓存主要向外提供两个功能:
- 精确查找;
- 模糊查找;
单个系统表的catcache中最多有4个查找关键字。当调用者使用4个关键字进行查找时,使用的是精确查找功能,返回的只有一条元组;当调用者使用不到4个关键字进行查找时,使用的是模糊查找功能,返回的可能有多个元组。所知道的范围内,pg_proc这个系统表对函数的查找是会使用到模糊查找的功能的。
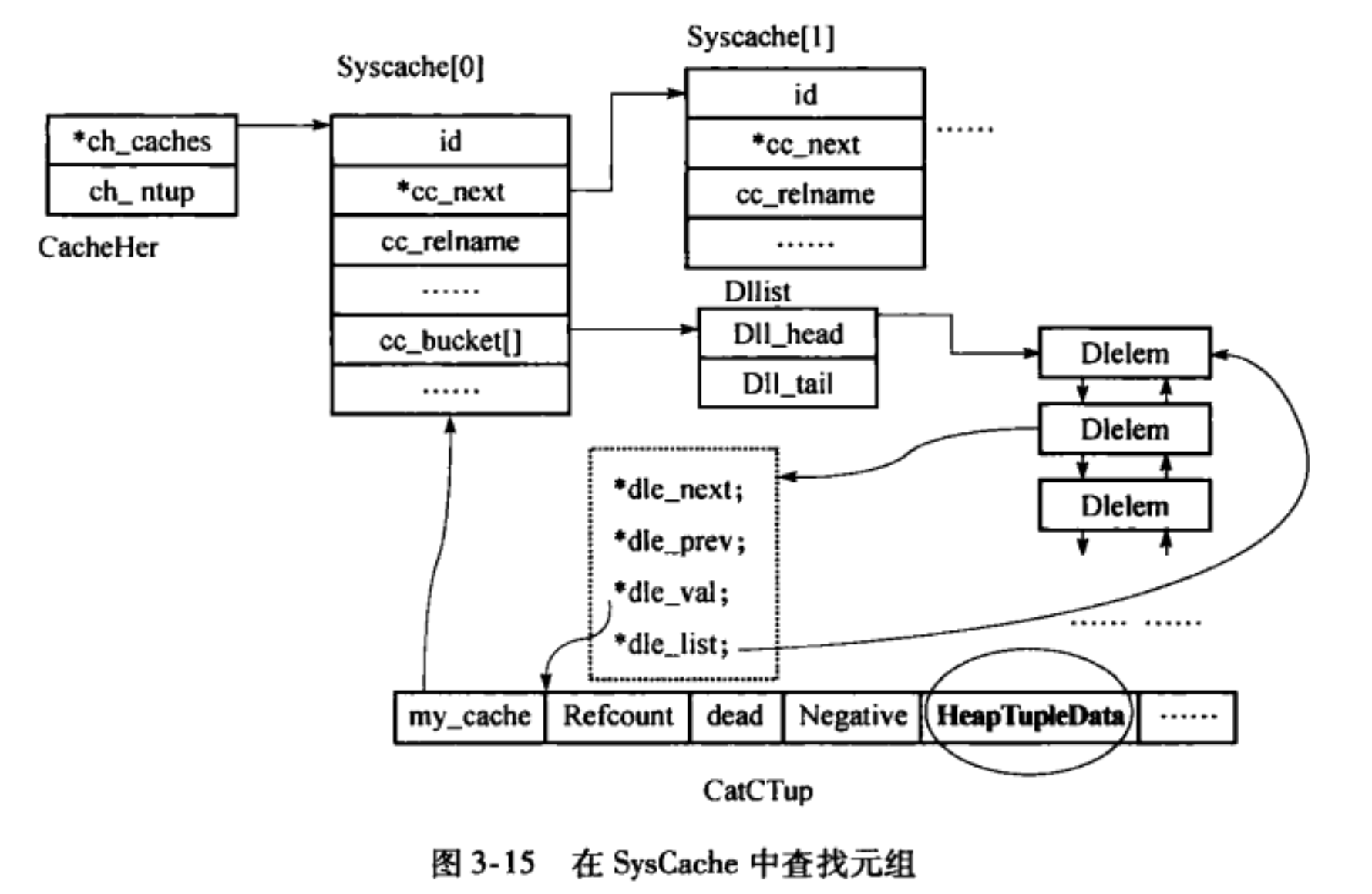
这个图给出了从catcache中查找元组的整体过程,它涉及到了catcache实现代码中的所有关键的数据结构。另外,要注意的是还有一个结构体是cachedesc以及它的数组cacheinfo静态数组,
/*
* struct cachedesc: information defining a single syscache
*/
struct cachedesc
{
Oid reloid; /* OID of the relation being cached */
Oid indoid; /* OID of index relation for this cache */
int nkeys; /* # of keys needed for cache lookup */
int key[4]; /* attribute numbers of key attrs */
int nbuckets; /* number of hash buckets for this cache */
};
========= 从cacheinfo静态数组中截取的一个元素 =========
{AttributeRelationId, /* ATTNUM */
AttributeRelidNumIndexId,
2,
{
Anum_pg_attribute_attrelid,
Anum_pg_attribute_attnum,
0,
0
},
128
},
可以看到,这个结构体主要给出了catcache中的几个关键要素:表OID; 索引OID; 查询关键字; 以及哈希桶个数。以给出的例子来讲,对系统表 pg_attribute的字段attnum进行了缓存,索引为 AttributeRelidNumIndexId, 查询关键字有2个分别为attrelid和attnum, 哈希桶的数目为128.正是依据这些基本的关键信息来建立起整个哈希表的。
对于上图中的详细介绍,可以参考pg数据库内核分析一书。除此外,还有几个要点是:
- 当使用精确查找时,直接将图中的HeapTupleData部分的数据返回给了调用者;
- 当使用模糊查找时,通过CatCList结构返回给调用者,调用者需要依次遍历这个链表;
- dead的缓存元组并不会马上清除掉,而是要等到它的引用计数为0时才会清除。如果这个缓存元组还位于某个CatCList中的话,还需要等待CatCList的引用计数也为0时,方才会被清除;
- 负元组的问题。负元组表示,使用某个关键字的查找结果是空,那个元组是不存在于这个系统表内的,所以无法在内存和磁盘上查找得到。为了避免反复在磁盘上去查找这样的元组带来的IO开销,所以将查询过的关键信息记录在了缓存中,并标识为负元组。
- catalog cache是一个只读缓存,意味着不可以进行写操作。当需要进行写操作的时候,必须使用与普通元组一样的shared buffer的写缓存路径。
Relation Cache
relcache要相对简单得多,它就是使用了普通的哈希表来管理表模式的。key为表的OID,value为表的模式信息(RelationData)。只要给出表的OID,就可以得到对应的schema信息。很显然的,如果查找不到的话,是会到磁盘上去scan相应的系统表,然后把信息拼起来,填充到哈希表中的,最后再返回给调用者。
Cache的同步与失效
cache的同步和失效是通过共享失效消息队列来实现的,其整体原理图如下:
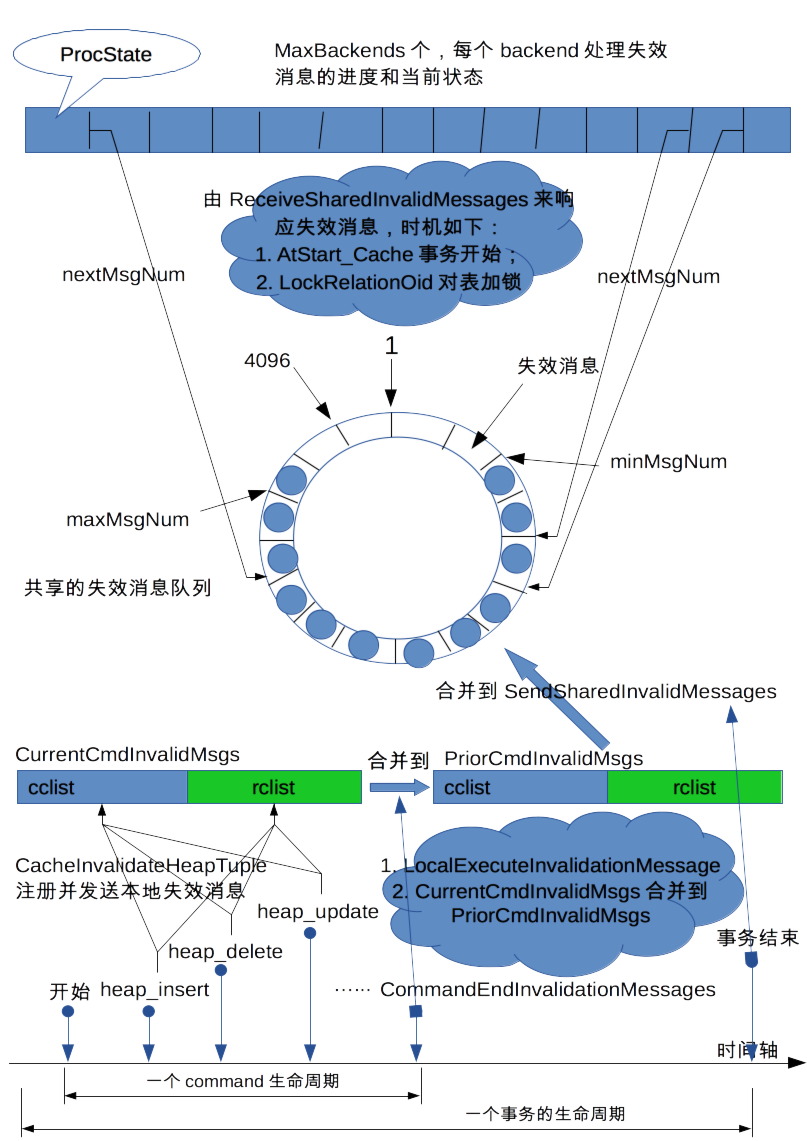
从上向下来看,所有进程共享一个循环消息队列,其大小默认为4096.该队列使用minMsgNum和maxMsgNum来标识失效消息的有效区域。当一个新的失效消息增加进来时(通过函数SendSharedInvalidMessages来实现),maxMsgNum向前移;当最慢的进程消费掉失效消息之后(通过函数ReceiveSharedInvalidMessages来实现),minMsgNum更新向前移.可以看到,minMsgNum表示的是所有进程处理失效消息的进度中的最小值, 而maxMsgNum表示的是当前所有失效消息可消费范围的最大上限。 每个进程消费失效消息的当前状态由结构体ProcState来表示保存,它其中最有意义的成员是nextMsgNum,记录了需要消费的下一个消息块位置。
/* Per-backend state in shared invalidation structure */
typedef struct ProcState
{
/* procPid is zero in an inactive ProcState array entry. */
pid_t procPid; /* 后端PID,用于发送信号 */
PGPROC *proc; /* PGPROC of backend */
/* nextMsgNum is meaningless if procPid == 0 or resetState is true. */
int nextMsgNum; /* 需要消费的下一个消息块位置 */
bool resetState; /* 后端进程需要重新加载cache的状态 */
bool signaled; /* 后端进程被发送了catchup信号 */
bool hasMessages; /* 后端进程有消息需要进行处理 */
/* 恢复过程中的后端进程才有效 */
bool sendOnly; /* backend only sends, never receives */
LocalTransactionId nextLXID;
} ProcState;
由此可以看出,后端进程对失效消息的处理主要有两种方式:
- 正常情况下,由ReceiveSharedInvalidMessages调用来实现失效消息的处理,其主要的响应时机有如下,
- 事务开始的时候,调用AtStart_Cache()函数来处理;
- 对表对象加锁的时候,主要由LockRelationOid()函数来处理响应;
- 被动地catch up;
- 来不及响应失效消息了,只能将整个后端进程的cache全部清洗掉,重新加载一次。当然,这种情形要尽量减少,否则的话,IO比较重。
对于第2种情况,在pg内核分析一书中写得是比较详尽的了,这里仅做必要的补充和说明。为了对第2种情况进行优化(即当整个队列里边全是没有消费的失效消息,而此时又有新的失效消息要增加),pg增加了两个变量lowbound + minsig。
- 第一个变量表示的是此次需要释放掉多少的空间,方才能够容纳新的无效消息;那么,nextMsgNum小于此值的所有后端进程必须把状态resetState设置为true,然后将自己的caceh全部清除干净,然后重新加载新数据;
- 第二个变量是说,它给出了一个可容忍的区域。nextMsgNum值在这个区域[lowbound, minsig]内的所有进程,可以容忍一段时间的追赶时间,赶紧消费失效消息向前赶,免得走前一个变量涉有的进程的路子。这就是catch up信号处理的来由。这个信号的响应是由最慢的那个进程开始的,要求它一次性响应完所有失效消息;然后,由该进程负责找到当前最慢的那个进程,然后通知那个进程赶紧追赶catch up;如此循环,调整后的minsig不再符合要求则停止。
下部分图中主要有几个关键的点。首先,一个完整的事务由1到多个命令(command)组成。而每个command内会有多个insert/delete/update的操作,这些操作会触发元组失效的本地消息;这些消息会通过处理函数添加到CurrentCmdInvalidMsgs列表中,记录了本次命令中新增的或者删除的元组。然后在下一个命令的边界,由CommandCounterIncrement函数来触发这些本地失效元组的处理,然后将CurrentCmdInvalidMsgs列表中的所有记录消息累积到另一个列表PriorCmdInvalidMsgs中去。每个命令都如此操作,到事务结束的时候,就会触发本事务的所有失效消息扩散到其他所有的后端进程,由函数SendSharedInvalidMessages来实现。
彩蛋
- 内存上下文相对相简单一些,使用者只需要像malloc/free/remalloc一样调用它的接口就可以了。但是要注意的几个点是
- 内存上下文是按照树形结构组织的;
- 处于树节点中的内存上下文进行reset/delete操作是会产生级联效果的,即它对所有的子树是生效的;
- 遗留了一个问题是:内存上下文怎么使用效率是最高的?能否有一个方法来监测它的使用指标不?