Maglev:一个快速可靠的网络负载均衡软件
论文:Maglev: A Fast and Reliable Software Network Load Balancer
术语
- network load balance 网络负载均衡
- service’s endpoint, 服务终结点
- generic routing encapsulation, GRE
- Direct Server Return, DSR
摘要
传统网络的负载均衡是通过硬件来做的,而Maglev是通过软件来实现的负载均衡系统,由google开发的, 主要为Google Cloud Platform提供网络负载均衡,从2008年服务至今。它的主要特点是:
- 专门为包的处理性能做过优化
- 配备了一致性哈希和连接trace特性,考虑了故障的问题
背景
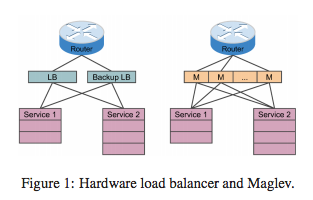
网络负载均衡器是谷歌网络基础设施的重要组件。在上图中,它同多个设备组成,逻辑上主要位于路由器和TCP/UDP服务器的之间。主要功能有两个: 匹配功能,将包映射到对应的服务器; 将包转发到服务的终结点上。
传统的负载均衡器由专门的硬件来实现,主要的缺点有:
- 扩展性差
- 无法满足高可用性要求
- 缺少弹性和可编程性
- 升级昂贵
使用软件化的负载均衡系统则可以解决上面的这些问题。设计和实现这样的系统有较高的复杂性和挑战:
- 系统中的每一个机器个体都必须提供高吞吐量
- 系统作为一个整体对外提供连接的持续性(connection persistence):属于相同连接的包应该发送给相同的服务终结点;
系统总述
Maglev是部署在谷歌的前端服务的位置上,包含了大小可变的集群。上图是一个简化了的架构。
谷歌对外提供服务是使用的VIP,这不同于物理IP;一个物理IP对应于一个network interface,而一个VIP对应于Maglev背后的多个服务的终结点。Maglev通过BGP把VIP告知路由器,然后路由器把这个VIP告知谷歌的骨干网,再接着由骨干网转而告知整个因特网。最后,整个VIP将会被整个网络全球可访问。
当用户敲入www.google.com的时候,浏览器将向DNS发起查询,DNS服务则会考虑到用户的物理位置以及每一个服务的负载,告知用户一个最近的前端服务、并把对应的VIP也一并给用户。然后,浏览器将会使用这个VIP建立一个新的连接。
当路由器接收到这个VIP包后,它把这个包通过ECMP转发到其中的一个Maglev机器上。这个Maglev机器接收到这个包后,它首先要选择与此VIP相应的一个服务终结点,使用GRE把外部IP头打包进这个数据包里,这样这个包就可以转发到服务终结点。
当数据包到达选好的服务终结点后,会对包进行解封并消费。响应包会带上VIP和用户IP放进IP包里边,我们使用DSR把响应直接发送给路由器;Maglev不需要处理返回包,这种包一般都比较大。本论文主要聚焦的是进来的用户阻塞问题,DSR的实现不在本论文之内。
Maglev的两个主要作用是:
- 告知路由器它的VIP地址;
- 把进来的数据包给后端的服务终结点;
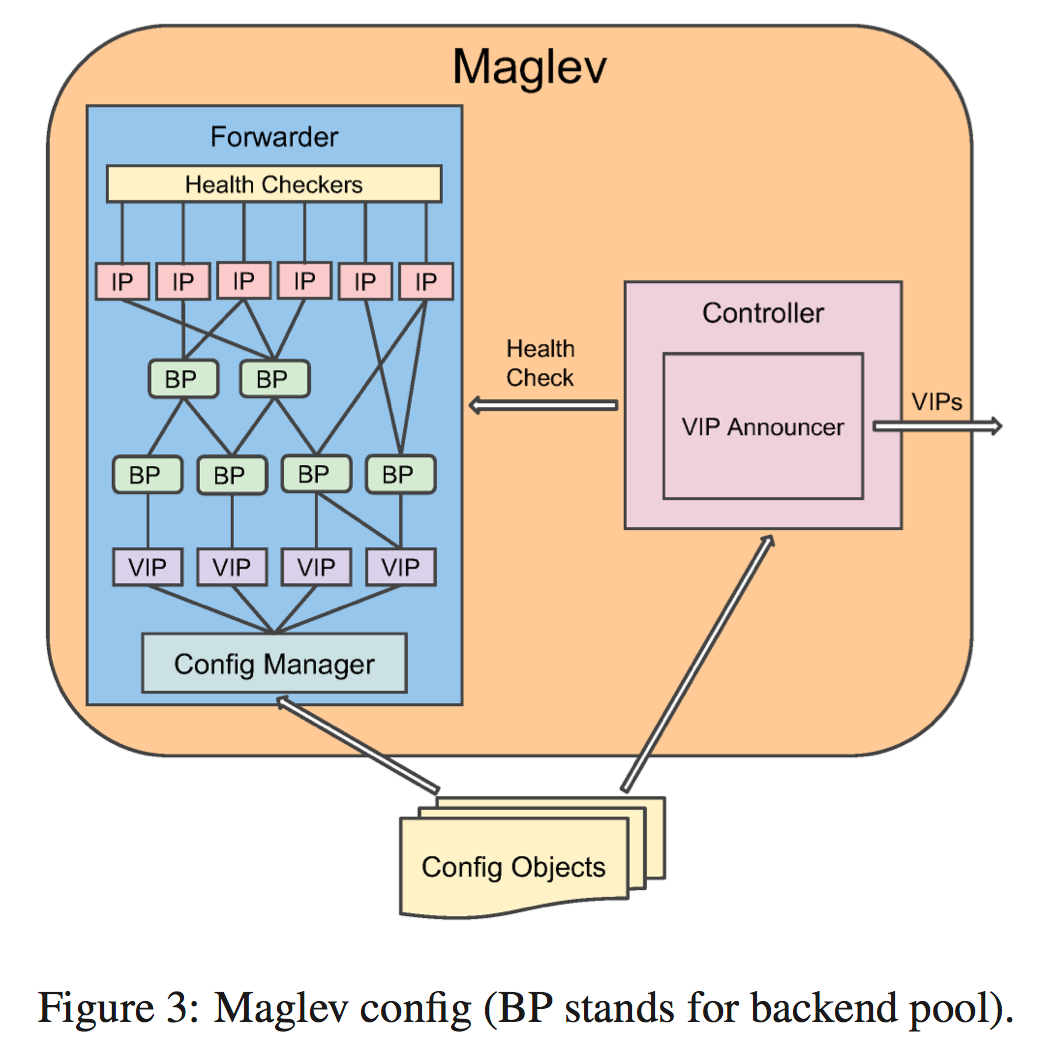
所以每个Maglev都配置有一个控制件和一个转发件(示图),这两部分都需要从配置对象中了解到VIP信息,要么是从文件 中读取,要么是通过RPC从外部系统中读取。
控制组件会周期性地检查forwarder的健康状态, 以保证路由器发送过来的数据包是转发给健康的Maglev机器的。
每一个VIP配置有一个或多个后端池(图中的BP),除非特别指定,一般后端就是服务的终结点。一个后端池可能包含对应服务终结点的物理IP,也可能递归地包含别的的后端池。每一个后端池关联着一个或者多个的健康检查方法,以确保数据包转发到的是健康的服务点。
config manager负责解析和校正配置对象。所有配置的更新都是原子性的。
可以对maglev进行shard配置,这样可以为不同的VIP集合进行配置和服务。sharding技术提供了性能的隔离性,并确保了服务的质量。
forwarder的设计和实现
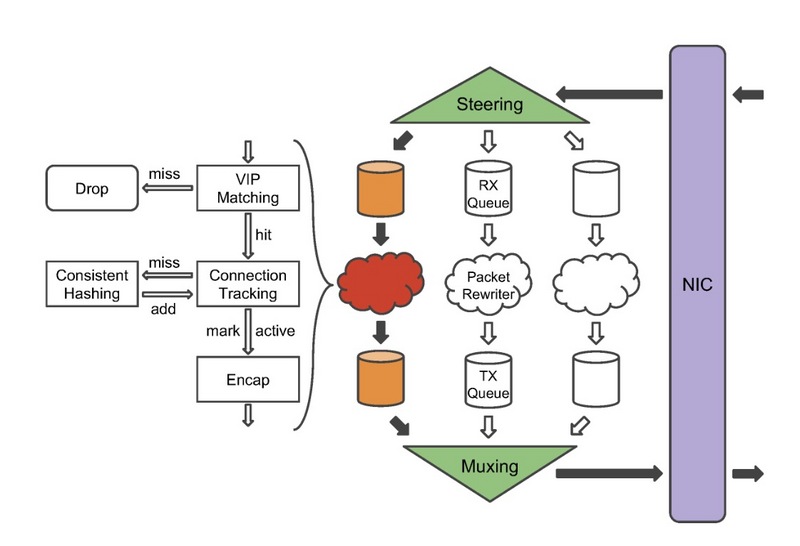
linux内核并不涉及这些。总体来讲,forwarder接收从NIC发来的数据包,将它们用适当的GRE/IP头重写之后,再把它们发回给NIC。
forwarder中的steering模块先处理接收的包,首先计算该包的5元组哈希值, 然后依据哈希值把包转给不同的接收队列。每个接收队列依附于一个数据包的重写线程。 重写线程首先会检查数据包是否能够匹配到某个配置好的VIP上,这样可以过滤掉那些并属于任何VIP的数据包;然后,再重新计算5元组的哈希值,然后在连接追踪表中查找是否存在这个包。
连接追踪表记录了最近连接的后端选择结果。如果查询找到并且匹配的后端仍然是健康的,那么直接重用选择结果。否则,线程需要通过一致性哈希表模块来选择一个新的后端,同时向连接追踪表中新增一个条目。如果没有一个后端是可用的、可选择的,那么这个包就会被丢弃。 一个线程维护一个连接表,这样子可以避免访问竞争。
后端选择成功后,线程会把包进行重写(加上GRE/IP头),再把它发送到附属的传输队列上; 然后,由muxing模块poll所有的传输队列,然后交给NIC。
快速的数据包处理
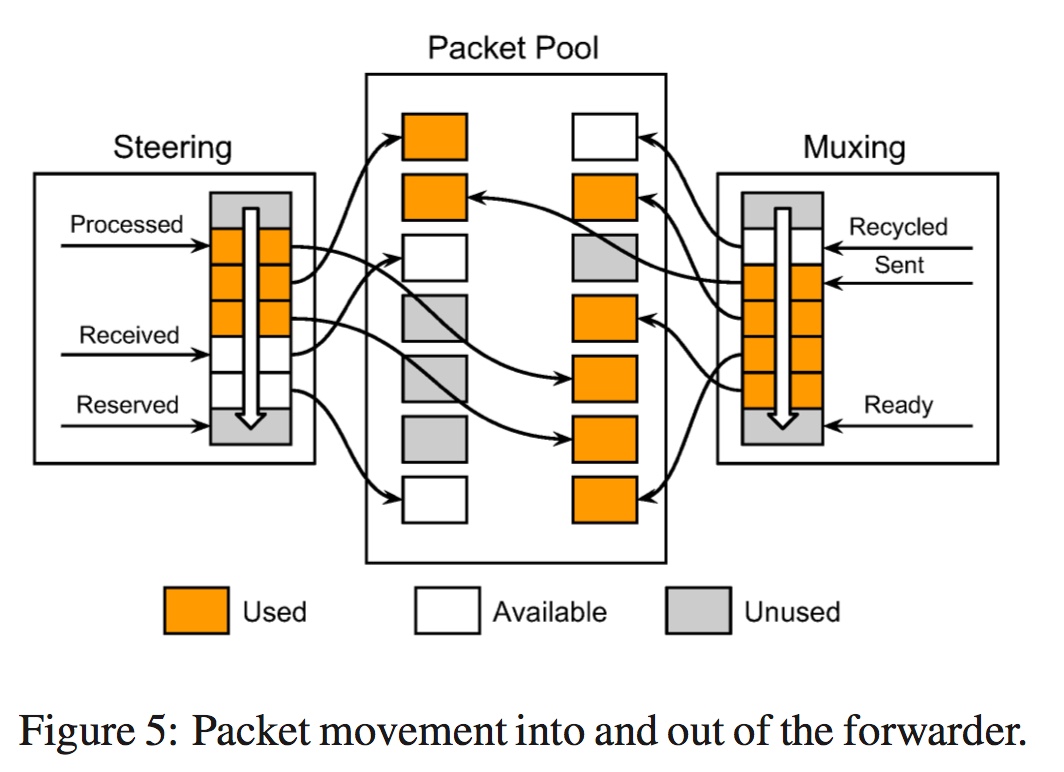
使用了bypass linux kernel技术,maglev是一个运行在用户态的程序。 在启动的时候,会预分配一个数据包池,用于NIC和forwarder之间共享。steering和muxing模块各自会维护一个指针的环形队列,它们的指针指向包池中的数据包。二者都使用三个指针来维护各自的环形队列。
steering是接收端。当数据包从NIC来之后,新来的包要放在 p_received指向的位置,然后前移该指针。该数据包分发给对应的包线程后, p_processed指针前移。 对于无用的包,则使用另一个指针 p_reserved来维护,把数据包入在环形队列中之后前移该指针。
muxing是发送端。NIC将发送由 p_sent指针指向的数据包,然后前移它。 包线程重写后的数据包将放放置在由 p_ready指向的位置,然后前移该指针。 另外,它还维护着NIC退回来的数据包指针 p_recycled,放置数据包后前移该指针。
可以看到, forwarder中的数据包并不进行复制。另外,还做了几点优化:
- 在可能的时候,进行数据包的batch处理;
- 各个包线程之间不共享任何数据,以避免竞争;
- 将包线程挂在指定的CPU上以保证最佳性能;
每个包的处理平均时间是350ns。
后端选择
对于面向连接的协议 例如TCP,要求同一个连接的所有数据包要求发送给同一个后端。 对于这一点是通过两部分来达到的:选择一致性哈希表; 使用一个连接跟踪表来记录后端的选择。
连接跟踪表使用的是普通的哈希表,key是5元组哈希值,value是选择的后端;每一个哈希项都是固定大小的。
在我们的分布式环境中,仅有连接跟踪表(per maglev)是不够的。
首先,路由器并不保证连接的亲近性,无法保证具有相同5元组哈希的数据包就可以传递给同一个maglev;很简单的一种情形是,maglev机器集变化了。在maglev机器变化的同时,恰好后端也在变化,那么连接就可能断,maglev的连接跟踪表就有可能不正确。
另外一个理论限制是,连接跟踪表有着有限的空间可用。我们需要严格限定表的大小。
一旦上面的任何一种发生,我们都无法再依赖连接跟踪表来处理后端的变化。所以maglev还需要一致性哈希表来处确保可靠的包分布。
一致性哈希表
一致性哈希表的想法是,生成一个查询表,每一个后端占据该查询表中的一部分位置项。这种方法可以为后端选择提供两个属性:
- load balancing, 每一个后端接收到基本相同数目的连接,即需要更均匀地分布;
- minimal disruption, 当后端集合变化时,一个连接最有可能被发送到之前它所在的后端;即需要最小量的重分布;
效率
這里需要注意,如果 M 相当接近 N 的話,整体效率很容易落入最差狀況。但是如果 M»N ,比較容易將效率落入平均的狀況。
- 平均狀況: O(MlogM)
- 最差狀況: O(M^2)
其中:M 是表示 lookup table 的大小(必须是一个prime number).N是表示后端节点的个数。
流程
- 首先 Maglev Hashing 会先把所有的 Preference List 产生出來;
- 通过产生好的 Preference List 开始将节点一个个地加入并且生成出Lookup table来;
这个算法的实现过程将以代码实现来说明, 实现代码链接。在python 3.6下运行这段代码可以得到如下输出的信息:
- 初始化为5个后端, 查询表大小为13, 各个后端的prefer list为:
backend-0: prefer list => [3, 8, 0, 5, 10, 2, 7, 12, 4, 9, 1, 6, 11]
backend-1: prefer list => [2, 5, 8, 11, 1, 4, 7, 10, 0, 3, 6, 9, 12]
backend-2: prefer list => [3, 11, 6, 1, 9, 4, 12, 7, 2, 10, 5, 0, 8]
backend-3: prefer list => [10, 4, 11, 5, 12, 6, 0, 7, 1, 8, 2, 9, 3]
backend-4: prefer list => [7, 3, 12, 8, 4, 0, 9, 5, 1, 10, 6, 2, 11]
各个后端在查询表中占据的信息为:
backend-0, backend-1, backend-1, backend-0, backend-3, backend-1,
backend-2, backend-4, backend-0, backend-2, backend-3, backend-2,
backend-4
- 增加一个后端backend-5之后,(保持查询表大小不变),各个后端的prefer list为:
backend-0: prefer list => [3, 8, 0, 5, 10, 2, 7, 12, 4, 9, 1, 6, 11]
backend-1: prefer list => [2, 5, 8, 11, 1, 4, 7, 10, 0, 3, 6, 9, 12]
backend-2: prefer list => [3, 11, 6, 1, 9, 4, 12, 7, 2, 10, 5, 0, 8]
backend-3: prefer list => [10, 4, 11, 5, 12, 6, 0, 7, 1, 8, 2, 9, 3]
backend-4: prefer list => [7, 3, 12, 8, 4, 0, 9, 5, 1, 10, 6, 2, 11]
backend-5: prefer list => [3, 8, 0, 5, 10, 2, 7, 12, 4, 9, 1, 6, 11]
各个后端在查询表中占据的信息为:
backend-0(不变), backend-0, backend-1(不变), backend-0(不变), backend-3(不变), backend-1(不变),
backend-2(不变), backend-4(不变), backend-5, backend-5, backend-3(不变), backend-2(不变),
backend-4(不变)
可以看出,在新增或者移除后端节点之后,对于后端选择的结果基本是均匀的。另外,还有一个要注意的是新增节点之后,重新分布的数据必须是尽量最小的。(TODO: 这一部分需要比较一下其他一致性哈希表才能够更清楚)