PostgreSQL之页结构
PostgreSQL在磁盘上存储的页有好多种类型,像堆页(heap relation), 索引页(index relation), clog页(提交日志页), vm页(可见性映射表页), fsm页(空闲空间管理页),等等。 前两个是最经常打交道的页类型,其主要的结构如下图所示。
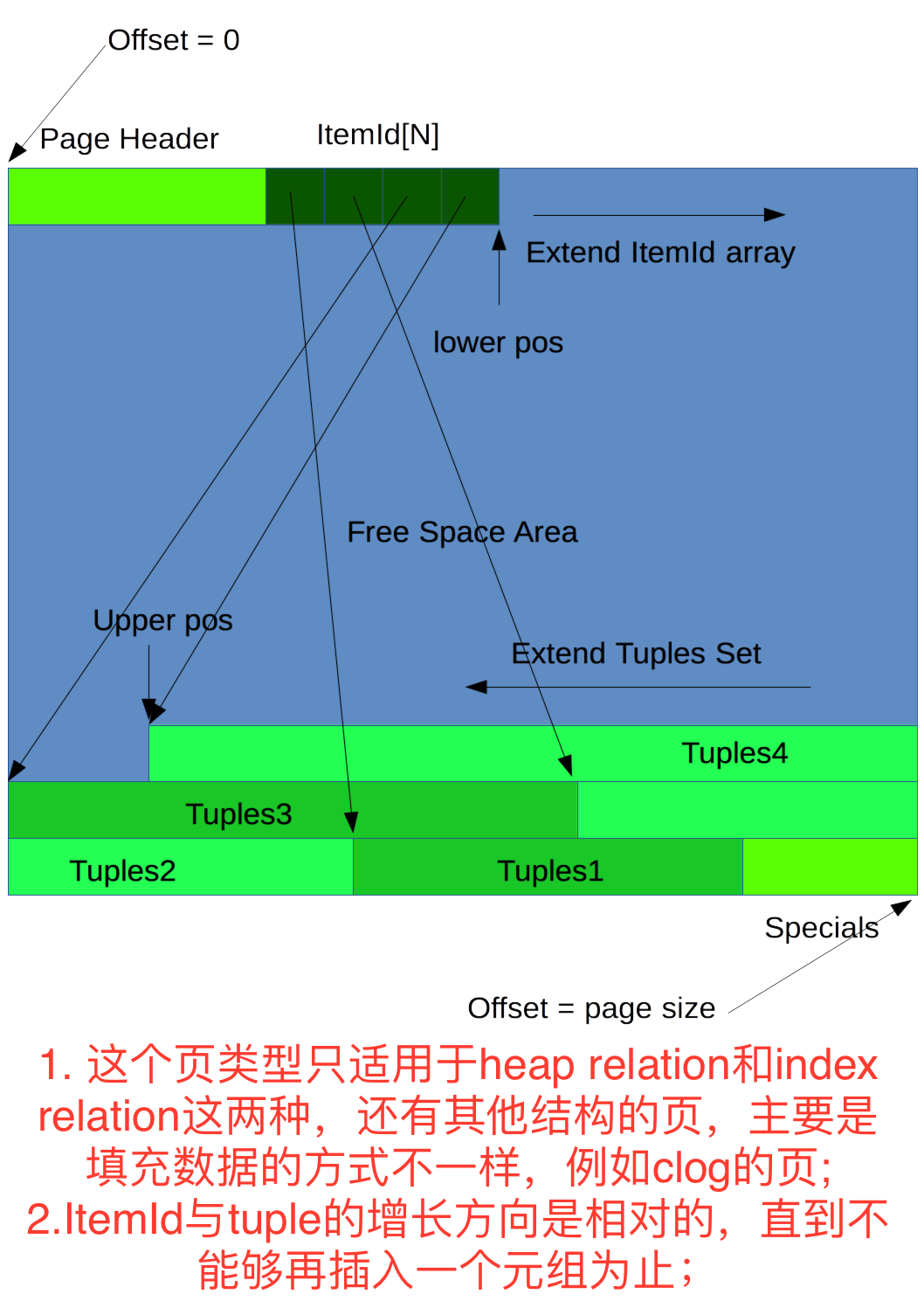
所述的所有页结构都采用经典的数据库行存页结构,即上图中所示的页头 + 数据部分 + 页尾部分(special部分)。对于堆页和索引页而言,使用的是所画的itemid + tuplues面对面增长的方式;对于其他页则采用了以某个单位为大小的数组方式。clog的单个元素大小为2bit,用于描述每个事务可能存在的4个状态之一;vm页的单个元素大小为1bit,用于描述对应的单个堆页是否存在无效的元组(已删除的、可回收的元组);fsm页的单个元素大小为1字节,用于描述对应堆页的可用空间有多大(fsm页本身有自己的管理方式,形成了树型结构+堆形结构来管理)。
主要以heap tuple来进行描述下面的内容。
页头
typedef struct PageHeaderData
{
/* XXX LSN is member of *any* block, not only page-organized ones */
PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog
* record for last change to this page */
uint16 pd_checksum; /* checksum */
uint16 pd_flags; /* flag bits, see below */
LocationIndex pd_lower; /* offset to start of free space */
LocationIndex pd_upper; /* offset to end of free space */
LocationIndex pd_special; /* offset to start of special space */
uint16 pd_pagesize_version;
TransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* line pointer array */
} PageHeaderData;
上面结构体中pg_linp是ItemId部分的开始地址,已经不属于页头的真实部分。页头大小是固定的,各个字段的含义主要如下:
- pg_lsn, 该页上次更改的xlog记录的最后一个字节的下一个字节,即LSN;
- pg_checksum,页的校验和值,这个字段在旧的版本是不存在的;
-
pg_flags, 与该页相关的标识
- PD_HAS_FREE_LINES, 该页的ItemId部分是有可直接重用的位置;
- PD_PAGE_FULL, 该页已满,不可再插入新的元组了;
- PD_ALL_VISIBLE, 该页内的所有元组是可见的,没有dead元组或者可回收的元组、已删除的元组;
- pg_lower, 上图中的lower pos位置,由该值来计算该页中的ItemId个数;
- pg_upper, 上图中的upper pos位置,表明了页中元组空间的最低位置,用来判定新插入的元组是否会与ItemId数据相重叠从而使得页数据被破坏,或者该页是否已满;
- pg_special, 上图中的页尾的预留空间的大小,用来计算页中元组的最高位置;
- pg_pagesize_version,这里面记录了页大小的版本,默认大小为8KB;
- pg_prune_xid, 用来记录最旧的清理该页的事务ID值,与lazy vacuum / prune page相关;
对于堆页来讲, pg_special的值为0,表明堆页是不存在预留空间的。在页没有满的情况下,中间的区域为空闲区域,时刻准备着新元组的插入。
ItemId
这部分区域紧接着页头部分,由pd_linp的第0个元素开始算起,相当于一个数组。其数目的计算公式为:
每一个数组元素的大小为4byte,信息由ItemIdData结构体来决定,主要记录了其对应元组的位置信息,包括了页内偏移量、对应元组的长度以及相应的标识信息。
typedef struct ItemIdData
{
unsigned lp_off:15, /* offset to tuple (from start of page) */
lp_flags:2, /* state of item pointer, see below */
lp_len:15; /* byte length of tuple */
} ItemIdData;
lp_off记录了相对于页起始位置的相对偏移值,用于说明了对应元组的位置,它使用了15个bit。lp_len记录了对应元组的长度信息,同样使用了15bit;这二者就可以决定页内单条元组的基本信息。lp_flags则使用了剩余的2bit,表示了4种不同的状态,
- LP_UNUSED, 表示该item是空闲的、没有被使用的。一般来讲,其对应的lp_len为0. 一般有两种情况:一是比当前pg_lowwer位置大的item, 它属于空闲范围之内; 二是虽然在比pg_lowwer位置小的item范围之内、但是对应的元组被删除掉且已从物理上回收空间、标识为可再利用的item。
- LP_NORMAL,表示该元组是正常状态的。当向一个页内插入一个元组后,该元组对应的ItemId就会打上这个状态标识;
- LP_REDIRECT, 表示这个item只是用来重定位另一个item的,它本身呢并不再指向某个元组了。这个标识是由lazy vacuum/prune page这两个动作过程中所打的,属于一个中间过程的标识。
- LP_DEAD, 表示这个item对应的元组是删除后且不再有事务去访问的死元组了,换句话说可以从物理磁盘上清掉了。这个标识是由lazy vacuum/pruce page这两个动作过程中所打的,属于一个中间过程的标识。这个状态会立即向LP_UNUSED转换。
这几个状态之间的转换关系图为:
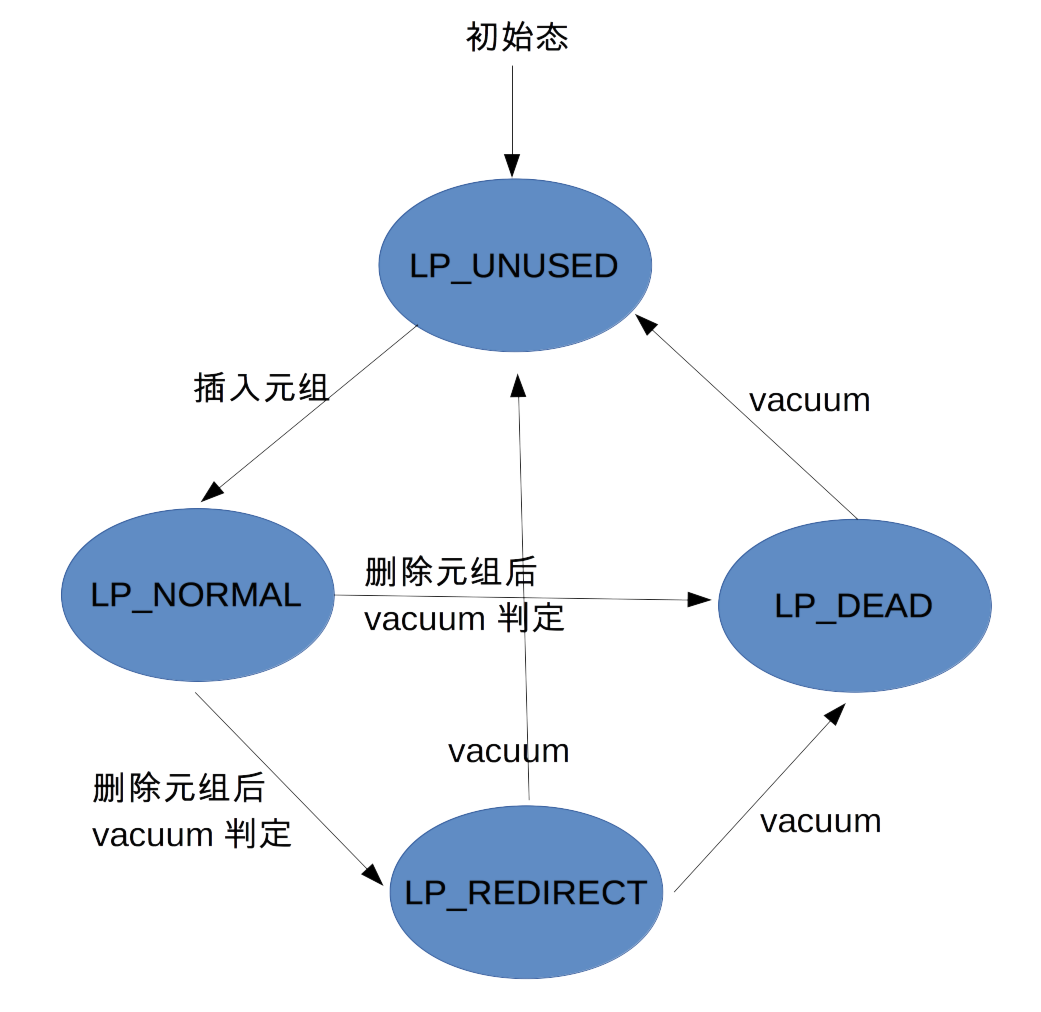
在一开始,一个item最初始的状态是未被占用的,插入的新元组会使用到这个。当这个元组删除(或者更新引起的删除)之后,lazy vacuum/prune page将使用vacuum规则来判定相应的元组是哪种状态,主要关心两种状态:dead; recent dead。
- 某条更新链上的、处于同一个页内的所有元组,如果全部元组判定结果为dead, 那么,
- 链上的第一个元组对应的item被标为LP_DEAD状态;
- 其他元组对应的item将全部被标为LP_UNUSED状态;
- 某条更新链上的、处于同一个页内的所有元组,如果前一部分元组的判定结果为dead,后一部分的元组判定结果为recent dead,那么,
- 前部分元组(不包括链上的第一个元组)对应的item将被标为LP_UNUSED状态;
- 链上的第一个元组对应的item被标为LP_REDIRECT,指向后一部分的第一个元组item;
需要注意的几点是:
- 因为对单个页的扫描是从1-最大的itemid的,而更新链的第一个元组并不一定在较小的item位置上,那么,就有可能将一个真正的更新链切割为两条或者更多的更新链;
- 那些recent dead的元组将会在后续的、下一轮lazy vacuum/pruce page操作中再次被标为unused的,从而将item再次回收利用了。
- 上图中,从LP_REDIRECT到LP_UNUSED的状态在代码实现中是存在的。从理解的层次来讲,不太容易理解的,可以不用太纠结这个状态的转换。考虑一个特殊的情况,就是页内HOT链上只有一个ItemId,并且它的状态就是LP_REDIRECT,那么对于这个独立的元素,在进行vacuum的时候,就是会可以直接进入到unused状态的了。
元组区域
元组本身的结构和操作不在本部分说明。
元组区域会随着元组的插入的操作不停地变化,会向低方向增长,或者不变化(有部分是inplace update,直接在原位更新)。删除操作只会更新某个元组的头部数据,不会导致区域的收缩。lazy vacuum/prune page操作则会将已删除掉的元组从磁盘上进行物理回收,并进一步对页内的结构进行紧凑整理,使得元组区域缩紧,向高偏移方向收紧。
页尾
堆页是没有页尾部分的。索引页使用页尾部分来存储一些必要的信息,例如,btree索引会使用这部分信息构造成整个平衡二叉结构来。
空闲区
空闲区正常情况下,里面的数据全是0. lowwer位置和upper位置是空闲区域的两个守卫者,这二者始终要遵守着一小一大的关系,不可超越这个关系,否则整个页数据必然覆盖。
插入一个元组
插入一个元组的过程相对要简单的多。主要参考函数PageAddItemExtended();旧版本的话,应该是函数PageAddItem()。这个函数会把要求插入的元组放到相应的页内位置上,并将对应的位置信息返回出去。如果入参的offsetNumber指定了一个有效的位置 ,则会尝试将元组放在指定的这个位置上;如果这个位置在该页内并不在有效范围之中,则会尝试自己找一个位置的。调用者在执行成功后,需要对相应的ItemId信息进行设置。
彩蛋
为什么prune page的过程中,需要处理每一个单独的HOT链,而不是直接对页内所有元组循环处理完就OK呢?
根本上是为了保持索引信息与堆元组信息之间的HOT关系。举个例子来说明。
索引页1上有元组i1,对应堆页上的元组t1,并且HOT链为:
i1
|
*
t1 --> t2 --> t3 --> t4 --> t5
^ ^ ^ ^ ^
| | | | |
Root Dead Dead Recent Recent
HOT链上各个元组的判定关系如上所述,t2/t3都为DEAD元组,那么t1也必定为DEAD元组;t4/t5元组则判定为recent dead元组,在这轮lazy vacuum/prune page中是不需要回收的。在元组回收之前, 此时索引元组还是可访问的;因为vacuum的顺序是,先处理heap page,再处理index page这样的一个顺序。那么索引访问会沿着整个HOT链前行,直到找到匹配的t4或者t5。肯定地,对于仍然可以访问的t4/t5元组之后,即使整个HOT链上的部分元组回收掉了,也需要保持这样的一个搜索关系存在。也就是说,Root元组是不可以回收的,因为它关联着索引元组i1和堆页内的元组t1;除非索引元组i1进行了相应的更新,记录了指向t4的信息,否则t1动不得。很明显,t2/t3回收之后,t1元组必然要指向t4元组的,否则的话HOT链就要断了。也正是因为如此,ItemId的状态中才会多出了LP_REDIRECT这个状态。
上面的解释中,还要注意的几点是:
- 页内的链处理的一定是HOT UPDATE链的,而不是普通的更新链;
- 更新链上的元组是用元组头部的信息关联起来的,在回收元组之后,这个关联就需要使用ItemId中的flag标识和offset来关联起来了。
为什么创建表的表空间与数据库的默认表空间相同的话,它在pg_class中存储的表空间OID为0呢?
这是由于新建的数据库是可以使用已有数据库作为template的,并且新建的数据库是可以指定自己的表空间的,即与template数据库的表空间不一样。如果在模板数据库中,创建的表(例如系统表pg_class等)与数据库默认是具有相同的表空间的,那么在拷贝磁盘文件的情况下,如何保证不作任何修改,也能够保证这些信息的一致性呢?PostgreSQL使用了一点hack的方法,就是使用了一个固定的值0.平常情况下,它作为一个无效的OID,但是用在这里是作为hint存在的,即表的表空间与所在数据库的默认表空间是一致的、相同的。